ニューラルネットワークの基本
初期のニューラルネットワーク
ニューラルネットワークとは、足し算や掛け算と言った単純な計算ができるニューロンを組み合わせることで、人間の脳のように高度な学習をさせる機械学習の一つの方法です。初期のニューラルネットワークは以下のようなものです。足し算と掛け算を計算して、その値が0より大きければイヌ、そうでなければネコと判断します。入力にかける値、判定のしきい値を学習します。

MNIST へのニューラルネットワークの適用
上の図ではネコかイヌかに分ける例だったので、最終的に値を1つだけ出力して、それで判断すればよかったです。しかし、MNISTは10個に振り分けますので、1つだけの出力では足りません。通常、N個のクラスに分けるときはN個の出力を用意します(2個にわけるときは、2個でも1個でもできます)。一般的に出力値が大きいクラスを予測値とします(以下の図では 0 が予測される)
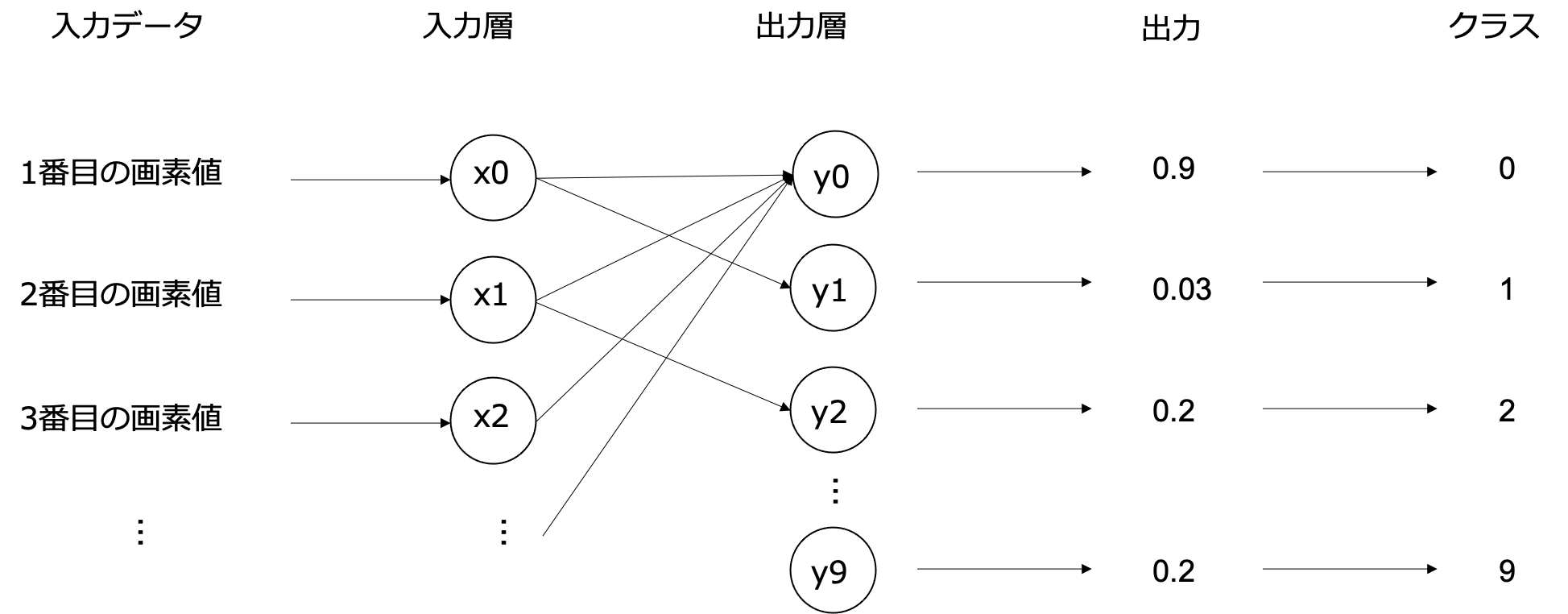
上記のグラフを tensorflow で実装したものが以下になります。
TensorFlow 2 の場合
ラベルの情報が整数 (int) である必要がありますので、 事前に以下を実行して整数に変換します。
y_train=y_train.astype(int)
y_test=y_test.astype(int)import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10)
])
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.compile(optimizer='adam',
loss=loss_fn,
metrics=['accuracy'])
model.fit(X_train, y_train, epochs=5)- tf.keras.layers.Dense(10) は、入力から掛け算と足し算を行う Dense Layer と呼びます。10は出力数を表します。
- tf.keras.losses.SparseCategoricalCrossentropy はニューラルネットワークで学習するときに、予測値と正解値の誤差を計算する式です。複数のクラスを扱うときはこの CrossEntroy を使います。Crossentropyを計算する前に、通常、値が確率に変換されている必要がありますが、今回は Dense の計算結果をそのまま扱うので from_logits=True を指定して、Crossentropyを計算する際に変換します。
- model.compile では、学習に必要な以下の情報を与えます。
- optimizer: 誤差を使ってどのように学習するかの方法
- metrics: 学習時にあわせて表示する評価指標です。accuracy は精度です。
- model.fit ではこれまでと同様にデータを与えます。深層学習では何回学習するかをepochで指定します。
急に入力することが増えてきて混乱するかもしれませんが、まずは model の部分を変えることに注目しましょう。
Practice 10
コードを実行してみましょう。時間があれば epoch を増やして再実行し、精度がどこまであがるか試してみましょう。
テストデータに対して予測する
scikit-learn を利用した場合と同様に、テストデータをモデルに入力して予測してみましょう。 予測には predict を利用します。
predictions = model.predict(X_test)
predictions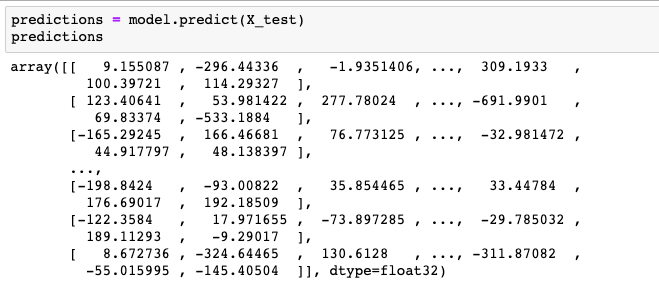
予測結果として、値の大きい正または負の値が得られました。これまでと異なって、ラベルや確率は返ってきていません。 確率を得るためには softmax という関数をかける必要があります。モデルの中で softmax を実行する方法もあります。 ここでは最初 (0枚目) の画像に対する確率を表示してみます。
from scipy.special import softmax
probability = softmax(predictions, axis = 1)
probability[0]この確率が最も大きいインデックスがラベルに相当します。値が最大のインデックスを探す関数 argmax を適用して、そのインデックス (=ラベル)を探しましょう。
import numpy as np
np.argmax(probability[0])
Practice 11
上記の予測した最初の画像ラベルと、正解のラベルを比較してみましょう。正解のラベルは y_test に全て保存されています。
精度を評価する
scikit-learn の場合と同じように精度を評価してみましょう。上記の応用でまずラベル y_predict を予測することから始めます。 すべてのデータの確率に対して argmax を適用すれば良いので以下を実行しましょう。この際、最大値を調べる方向が2方向あります(1ラベルに関して10000画像から最大値を探すのか、1画像に関して10種のラベルから探すのか)。ここでは後者に相当しますので axis=1を指定します (前者は axis=0)。
y_predict = np.argmax(probability, axis=1)これで準備が整いました。
Practice 12
scikit-learn の accuracy_score の関数を使って、y_predict と y_label から精度を評価してみましょう。
また scikit-learn を使うことも可能ですが、機械学習フレームワークを keras と scikit-learn で行ったり来たりしたくないこともあると思います。keras にも精度を評価するための関数があり、keras だけで学習・評価を完結できます。以下を実行してみましょう。scikit-learn の場合と同じ結果が得られましたか?
model.evaluate(X_test, y_test, verbose=2)参考
https://www.tensorflow.org/tutorials/keras/classification?hl=ja