決定木
決定木とは
決定木は以下の図のように「重さが5kg以下かどうか」「飛ぶことができるか」のようなルールでデータを振り分けていく方法です。このルールの部分を大量のデータで学習するのが決定木です。機械的にルールが計算されるので、ここまでわかりやすい決定木ができることはほぼありませんが、どのような振り分け方をしているかはわかります。そのため、機械学習がよくブラックボックスだといわれるのに対し、決定木は解釈可能なモデルといわれます。
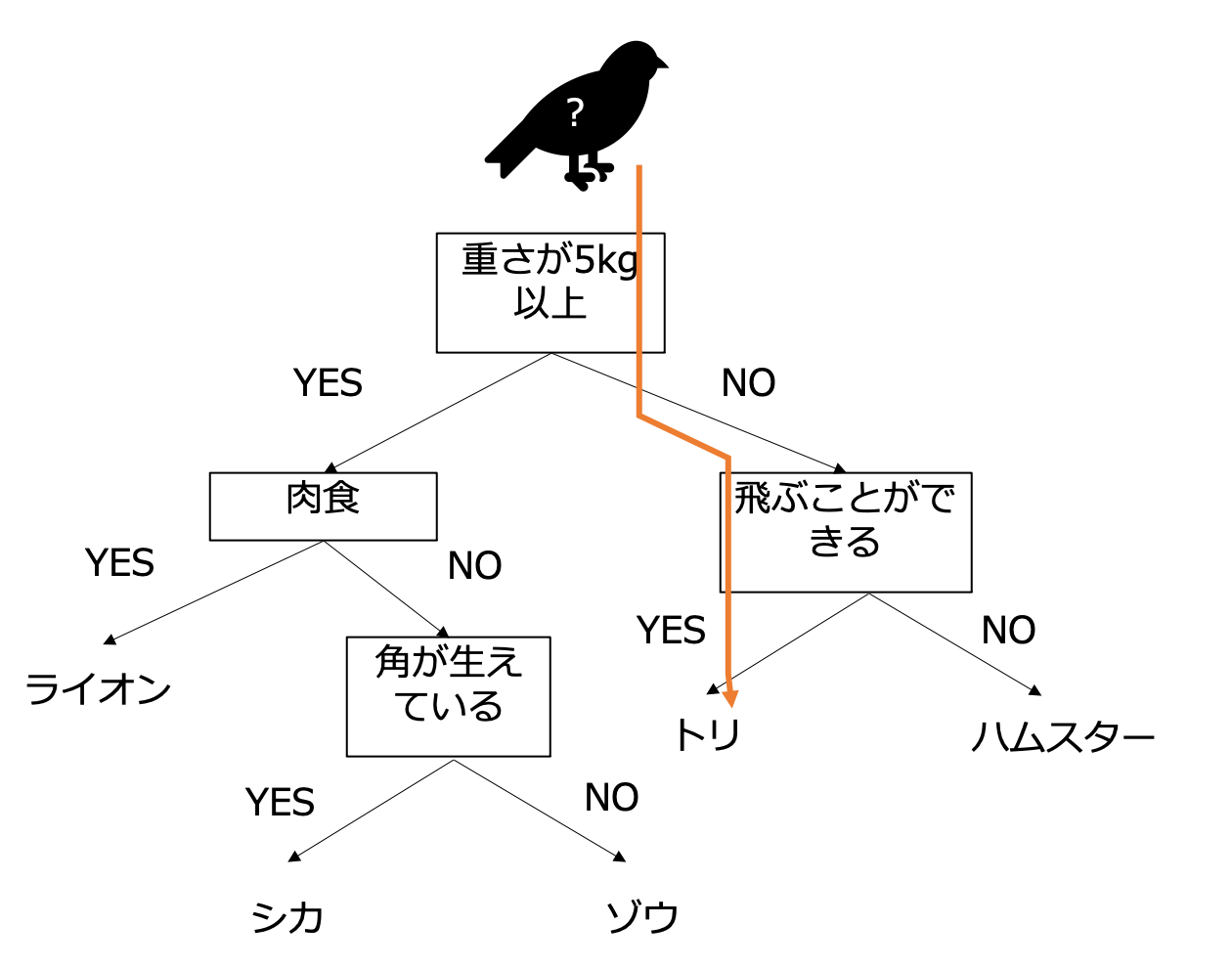
画像分類に適用する場合は、「N 番目の画素の明るさが K 以上かどうか」のような直感的には理解し難いルールができあがります。
決定木の実装
scikit-learn を利用して決定木を実装しましょう。決定木の使い方は scikit-learn のページの Examples に書かれています。ノートブックで使えるように転記したものが以下になります。
from sklearn import tree
X = [[0, 0], [1, 1]]
y = [0, 1]
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, y)
print(clf.predict([[2., 2.]]))
print(clf.predict_proba([[2., 2.]]))主に以下の4ステップで構成されています。
- この例では以下が既存のデータとして与えられていて、未知のデータのラベルの推定に利用します。
- データ X: [0, 0], [1, 1]
- ラベル y: 0, 1
- 機械学習のアルゴリズムのうち、決定木分類 DecisionTreeClassifier を呼び出します。
- fit を呼び出すと与えられたデータに対して学習を行います。決定木の場合、データからルールを作成します。
- 未知データを推定します。ラベルを推定する関数は predict です。predict_proba はラベルごとに推定の確率を返します。確率が大きいものをラベルとして推定することもできます。
Point
上記の処理の流れはk-近傍法と同じであることに気づくと思います。
Practice 6
上記のコードを Jupyter Notebook で実行してみましょう。
決定木の MNIST への適用
上の例を少し書き換えて、MNIST のデータに決定木を適用してみましょう。 k-近傍法のときと同様に、Xに X_train, y に y_train を入力し、予測データに X_test[0] をいれます。 今回はサンプルコードをあえて表示しないので、ご自身で実装してみましょう。参考までにk-近傍法のコードは以下でした。
X = X_train
y = y_train
from sklearn.neighbors import KNeighborsClassifier
neigh = KNeighborsClassifier(n_neighbors=3)
neigh.fit(X, y)
print(neigh.predict([X_test[0]]))
print(neigh.predict_proba([X_test[0]]))Practice 7
- MNIST に決定木を適用するコードを書いてみましょう。
- テストデータの最初の画像を推論してみて、ラベルと比較してみましょう。
よくあるエラー1
カッコの数が左右であっていないと invalid syntax や unexpected EOF などになります。エラーの近くのカッコの数があっているか確認しましょう。
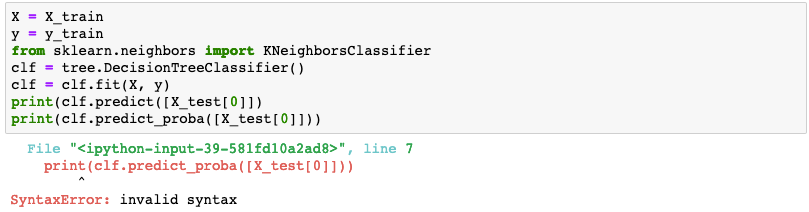
よくあるエラー2
X のデータは2軸のデータである必要があります。画像1枚 (例えば、X_test[0])だと画素のデータしかないので以下のようなエラーになります。
1枚だけ選ぶ場合は [X_test[0]] としてカッコでさらに囲んで軸を増やす必要があります。画像2枚以上 (X_test[0:2])だと、逆に囲んではいけません(3軸になってしまいます)。

よくあるエラー3
変数の名前を間違えると、not defined のエラーが出ます。大文字・小文字など気をつけましょう。

推論時間の測定
k-近傍法は推論時間が遅いというデメリットがありましたが決定木がどうか調べてみましょう。さきほどと同様に %%time をセルの最初に書いて、100枚の画像を予測をさせれば良いです。
Practice 8
100枚の画像に対する予測の時間を調べてみましょう。
ヒント
k-近傍法のときは以下のコードを利用しました。
%%time
neigh.predict(X_test[0:100])