データのダウンロードと確認
データのダウンロード
今回利用するデータセットは MNIST とよばれる手書き数字の画像データセットです。数字の画像が実際に対応している数字の情報も含まれます。この画像が実際に対応している数字のことをラベルと呼びます。以下の図では下段がラベルに相当します。
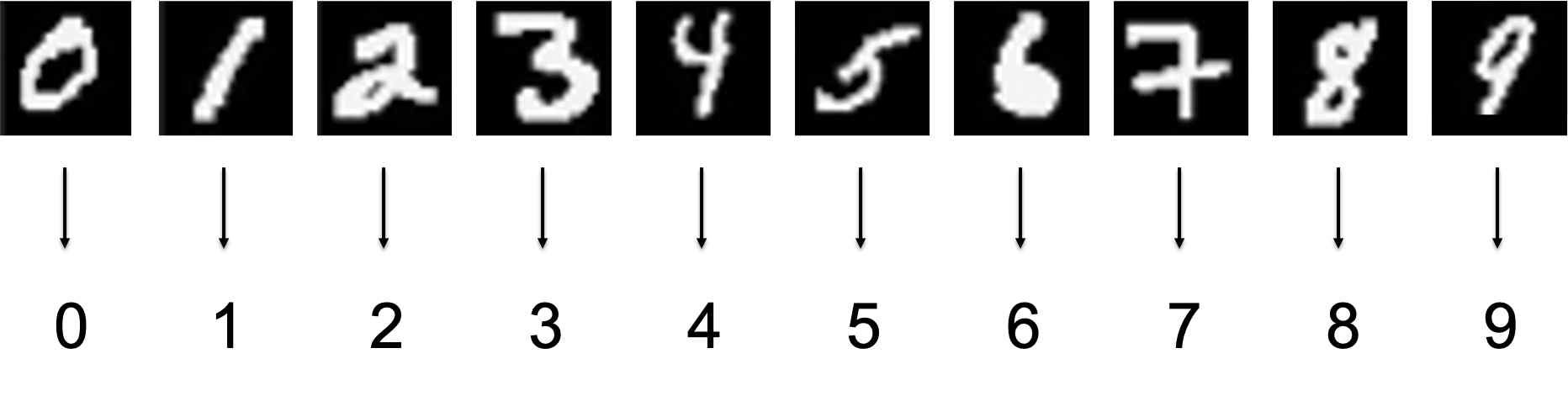
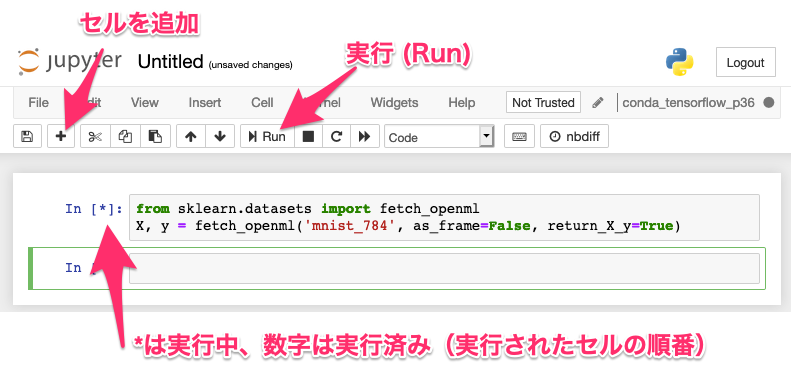
それでは MNIST の画像をダウンロードして実際に触ってみます。いろんな Web サイトからダウンロードして使うこともできますが、有名なデータセットであれば、機械学習のライブラリにダウンロードする機能がついています。以下のコードを Jupyter Notebook 上で実行しましょう。
from sklearn.datasets import fetch_openml
X, y = fetch_openml('mnist_784', as_frame=False, return_X_y=True)主に利用するボタンなどは以下の図のとおりです。実行時は実行するセルをクリックするなどして選択してください。実行は上の Run ボタンでも可能ですが、Shift+Enter や Ctrl(Command)+Enter での実行も可能です。
上記のプログラムでは、Xに画像データを、yにラベルのデータを保存しています。
データの確認
次に X とだけうって実行してみましょう。Xの中身を表示することができます。Xは画像データで、周りは黒 (=0) で白い数字の部分は 255 が入っています。一部しか表示されないので0しか確認できないと思います。
X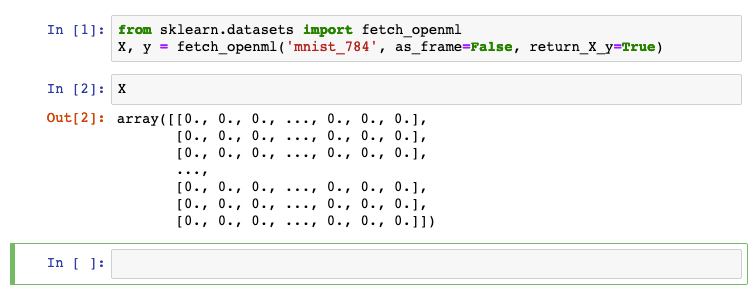
Practice 1
ラベルのデータ y を表示してみてください。ラベルの最初の数字はなんでしょうか。
データのサイズの確認
さきほどの方法ではデータの一部しか確認できません。どれくらいのサイズ(何個の数値が入っているのか)が気になると思います。shapeを使うと確認することができます。
X.shape
70,000 と 784 という数字がでました。この X は70000 x 784 のデータ構造をとっています。70,000というのは画像枚数で、784は1枚の画像の画素数を表します。MNIST の画像は縦28pixelで横28pixelなので掛け算すると784になります。
Practice 2
ラベルのデータ y のサイズは何か、まずはコードを書かずに考えてみましょう。ヒントは、1枚の画像に1ラベルが存在することです。答えがわかったら、Xのサイズを確認した方法 (shape) を使って、yのサイズを確認しましょう。
Point
すべての画像にはラベルがついている必要があります。画像ごとに1つのラベルがついているようなタスクでは、画像の数とラベルの数は同じになります。機械学習のタスクの中には、複数のラベルが付与されるタスクもあります (multi-label classification)。
画像の確認
数字だけだとわかりにくいと思いますので、画像で表示して確認しましょう。 matplotlib というライブラリを使えば画像を表示することができます。以下のコードでは、最初の画像 X[0] を表示します。Practice 1 で確認した数字と一致しているでしょうか?
%matplotlib inline
import matplotlib.pyplot as plt
plt.imshow(X[0].reshape(28,28), cmap=plt.cm.gray_r)