機械学習の結果の評価
評価の必要性
これまでk-近傍法や決定木を試しましたが、これ以外にもたくさんの機械学習アルゴリズムが存在します。データサイエンティストとしては当然、最も良いものを選びたくなります。最も良いものを選ぶためには、アルゴリズムを評価する仕組みが必要になります。
精度の評価
一番わかりやすい評価は、予測がどれくらいあたっているか精度に関する評価です。100個予測して50個当たっていれば精度は50%です。精度は高いほうが良いです。 それでは精度を求めてみましょう。そのためには予測結果が必要ですので、決定木の予測結果をまず保存しましょう。
y_predict = clf.predict(X_test)y_predict にはテストデータのすべての予測結果が入っています。これをテストデータの実際のラベルと比較して、合っている数が多いほうが精度が良いことになります。 一つ一つ比較する実装をしてもいいのですが、scikit-learn には精度を計算する関数が用意されています。
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)精度は良かったでしょうか? しかしここの精度とは、すべての数字がどれくらい正しく認識されているかを表していて、個々の数字がどれくらい正しく認識されているかは不明です。これを解決するために混同行列が利用されます。
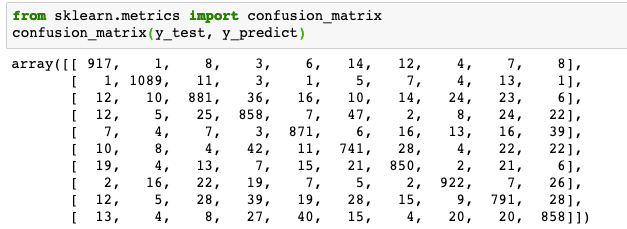
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_predict)左上の数字917は0を正しく0と判定した数、その下の1は1を0に誤って判定した数です。 左上から右下の対角線上にのっている数字が正しく判別された数です。それ以外は誤った数です。 以下の混同行列をみると3を5と間違うケースが多いようです。この結果は、人によって変わります。