その他のアルゴリズム
Random Forest
決定木を発展させたもので大量のデータから、複数の決定木を作成します。複数の決定木から最終的な予測を行います。 データが多ければより高い精度を見込むことができます。
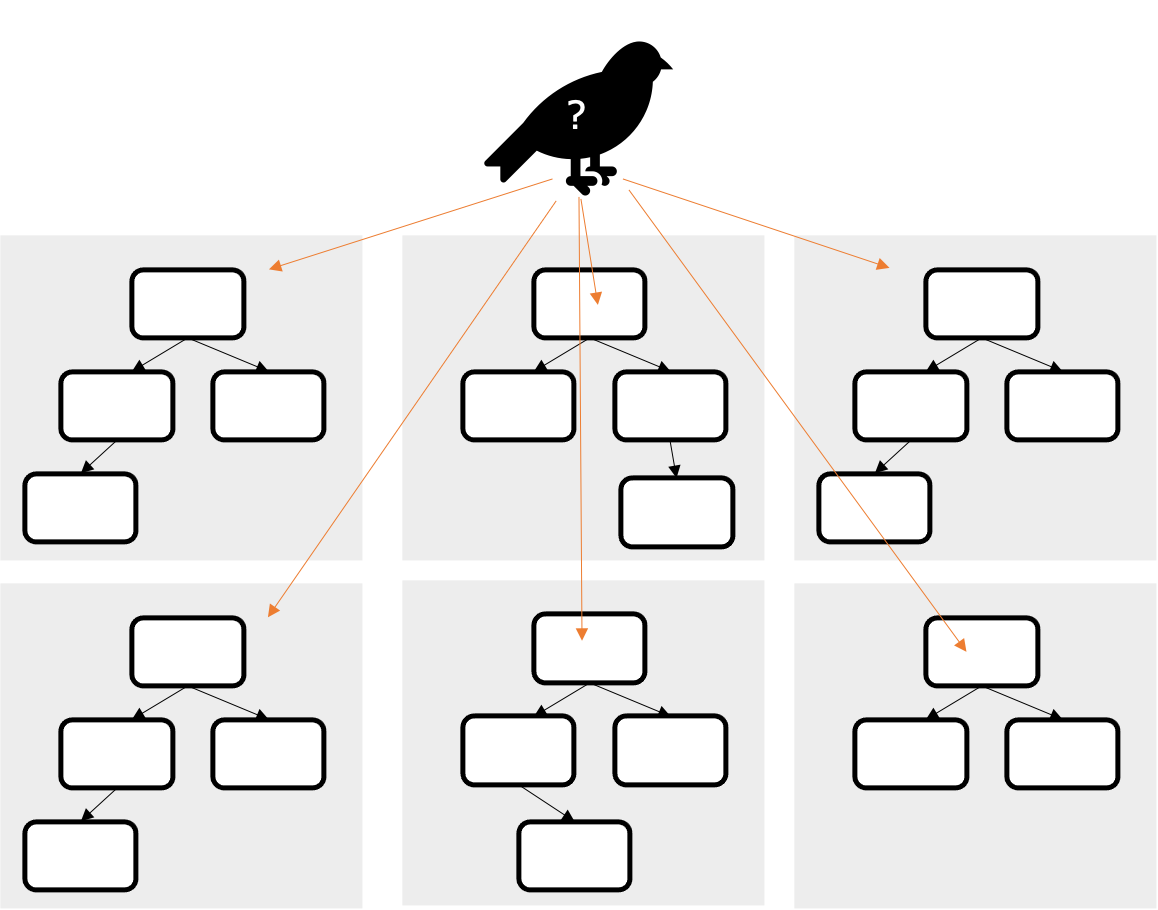
実装例は scikit-learn のページにあります。jupyter notebook 用に転記した学習用のコードは以下になります。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
clf = RandomForestClassifier(max_depth=2, random_state=0)
clf.fit(X, y)Practice 9
- Random Forest を MNIST に適用して、精度を評価してみましょう。
- Random Forest と決定木の精度はどちらがよかったでしょうか。
- max_depth を大きくすると高い精度が得られる可能性がありますが計算時間がかかります (10以下で試してみてください)