データのロード
Redshift serverlessにS3からデータをロードします。 この操作もQuery Editor v2上から操作可能です。
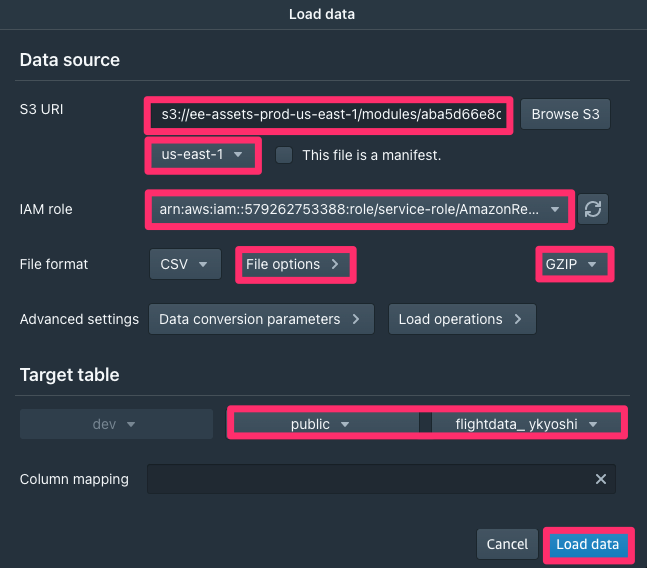
- 左上の「Load data」をクリックします。出てきたウインドウの一番上の「S3 URI」欄に、以下のURIを入力します
s3://ee-assets-prod-us-east-1/modules/aba5d66e8cd44378ba70a0427830efd5/v1/flightdata1/
URI入力欄の下の「S3 file location」をクリックし、ドロップダウンメニューから「
us-east-1」を選びます。S3からロードするためのIAMロールを設定します。
- Choose an IAM role をクリックします。ドロップダウンメニューに1つだけ選択ができる文字列(ロールのARN)が出てきますので、それを選びます。
- Choose an IAM role をクリックします。ドロップダウンメニューに1つだけ選択ができる文字列(ロールのARN)が出てきますので、それを選びます。
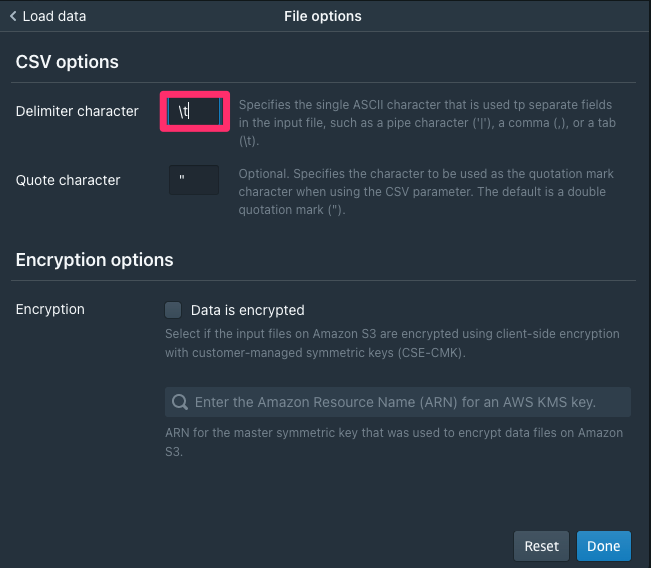
ロードするCSVの区切り文字の設定をします
- File format欄にある「File options」をクリックします。
- ロードするファイルはタブ区切りテキストとなりますので、開いたCSV optionsウインドウの「Delimiter character」で、
\tと入力します。 - 右下の「Done」をクリックします。
ロードするデータの圧縮方式の設定を行います。今回のデータはGZIP圧縮されています。
- File Optionsのとなりの「Nocompression」をクリックし、ポップアップメニューから
GZIPを選択します。
- File Optionsのとなりの「Nocompression」をクリックし、ポップアップメニューから
最後にTarget table欄から「Select a schema」をクリックして「public」を、「Select a table」をクリックして先ほど自分で作成したテーブル名を選択します。
選択したテーブルが自分が作成したものであることを必ず確認してください。
- すべて入力したら、右下の「Load data」をクリックします。
GUI上で設定した値で自動的に以下の様なSQLが生成され実行されることでS3からデータがロードされます。
SAMPLE SQL
COPY dev.public."flightdata_ ykyoshi"
FROM '<S3_BUCKET>' GZIP
IAM_ROLE '<IAM_ARN>'
FORMAT AS CSV DELIMITER '\t' QUOTE '"'
REGION AS 'us-east-1'SQL文のCOPYコマンドが自動生成・実行されてデータロードが始まりますので、しばらくお待ち下さい。ロードが終了すると、処理のサマリが表示されます。