自然言語処理によるSNSの医療情報抽出・分析
本ハンズオンでは、下記のようなユースケースの想定して実施します。
課題
- SNSやニュースなど様々な媒体の文章から、医療関連のキーワード抽出や エンティティのカテゴリ分類を自然言語処理を利用して自動化したい
- 医用画像に含まれるPHI(保護対象医療情報)の検出及び除去を自動化したい
実現すること
- 医療用に特化した自然言語処理サービスであるAmazon Comprehend Medicalを利用して、生体組織、状態、手順、薬、略語など、医療用語の膨大な語彙における、エンティティを抽出
- (Option)Amazon Comprehend MedicalによるPHIの抽出
実現しないこと/対象外
- Twitterにより取得したデータが直接、市販後調査/研究/GPSP等の業務に使えるか?については言及できかねます
- 本ハンズオンではクラウドのサービスを利用することによってご自分の業務が、
- 「どのように」
- 「すぐに」
- 「簡単に」
- 「安く」
構築できるか? を体感いただくことが目的となってます
本ハンズオンの概要
- 本ハンズオンでは、以下の内容を実施します。
- 医療用に特化した自然言語処理サービスであるAmazon Comprehend Medicalを利用し、Twitterの文章に対する医療関連のキーワードの抽出とエンティティをカテゴリ分類
- 当該結果をBIツールであるAmazon QuickSightを利用して分析
- 上記の内容ををサーバレスアーキテクチャで実施
- 本ハンズオン概要や自動構築のCloudFormationテンプレートは、こちらのサイトでも公開しております
全体像
- 下図のサーバレスアーキテクチャをQuickに作成し、医療情報の抽出と分析を実施します。
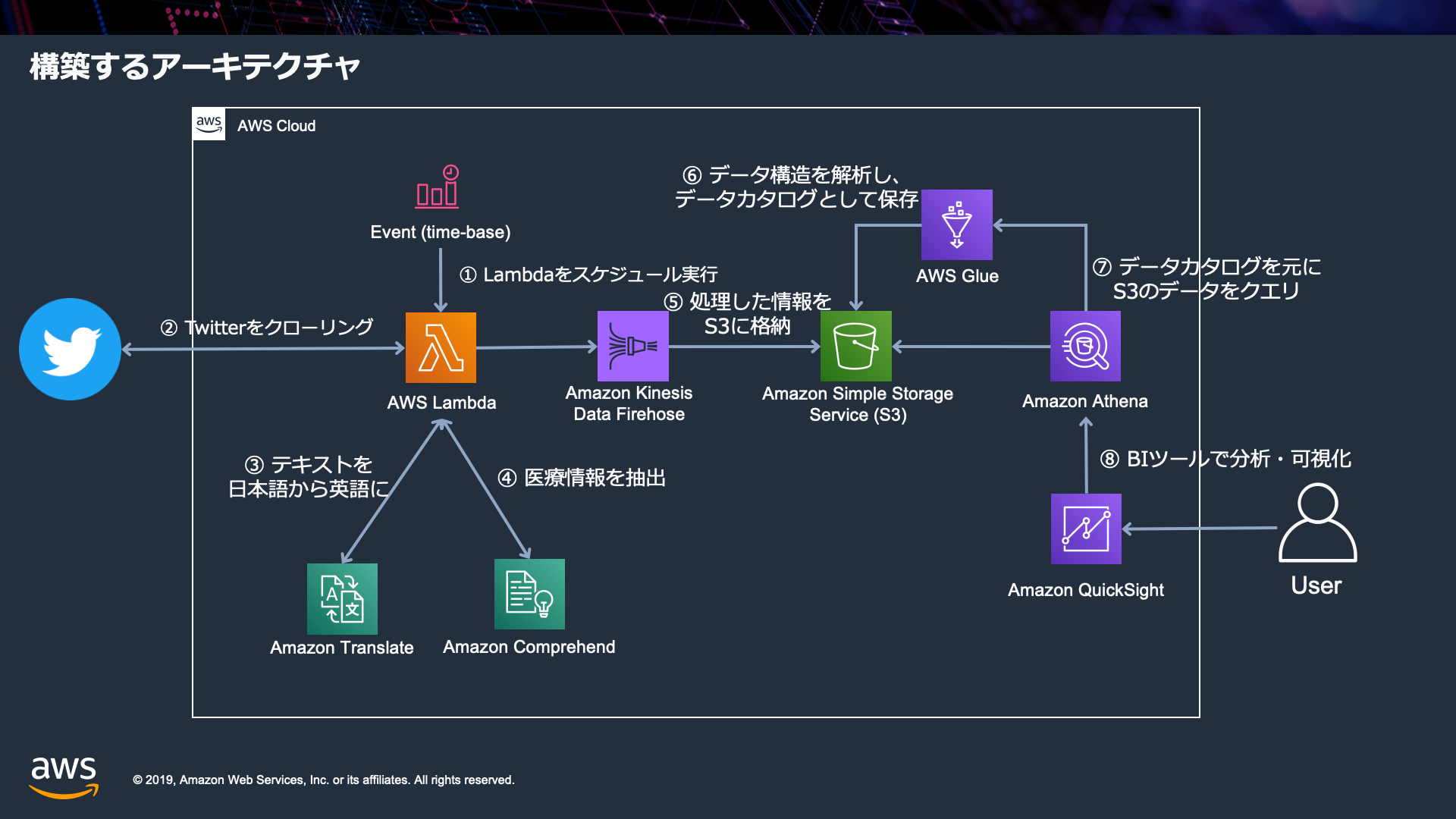
本ハンズオン内のワークフロー詳細
AWS LambdaでTwitterの任意のハッシュタグをクロールして文章を抽出
- AWS Lambdaをスケジュール実行(CloudWatch Event)してTwitterのAPIを叩き、任意のハッシュタグの文章を抽出します。
自然言語処理サービスを利用して、クロールした文章から医療関連のキーワード抽出とエンティティをカテゴリ分類
- 医療関連のキーワード抽出とカテゴリ分類をするため、自然言語処理サービスのAmazon TranslateとAmazon Comprehend MedicalをAWS Lambdaで呼び出して実行します。
結果をストレージに保管し、分析系のAWSサービスを利用して分析・可視化
- 抽出・分類結果をAmazon Kinesis Data Firehose経由でAmazon S3に保管し、AWS Glueでデータカタログ化します。
- このデータカタログを利用して、S3内のデータにAmazon Athenaでクエリ実行し、Amazon QuickSightで分析・可視化します。
それでは早速、始めてみましょう!
進め方
- テンプレートによる自動作成を行う場合は、次のページへ進んでください。
- 画面右中央の矢印をクリックして進めてください
- 手動でコンポーネントを作っていく場合は、こちらの1.コンポーネントの作成(手動構築版)へ進んでください。