CloudFormationによる自動構築
AWS マネージメントコンソールにログイン
AWS マネージメントコンソールにログインし、リージョンをバージニア北部に設定であることを確認
- CloudFormationのテンプレートから環境を自動構築します
- こちらを右クリックし、新規タブで開く
- 下記のようなCloudFormaionの画面が表示されます
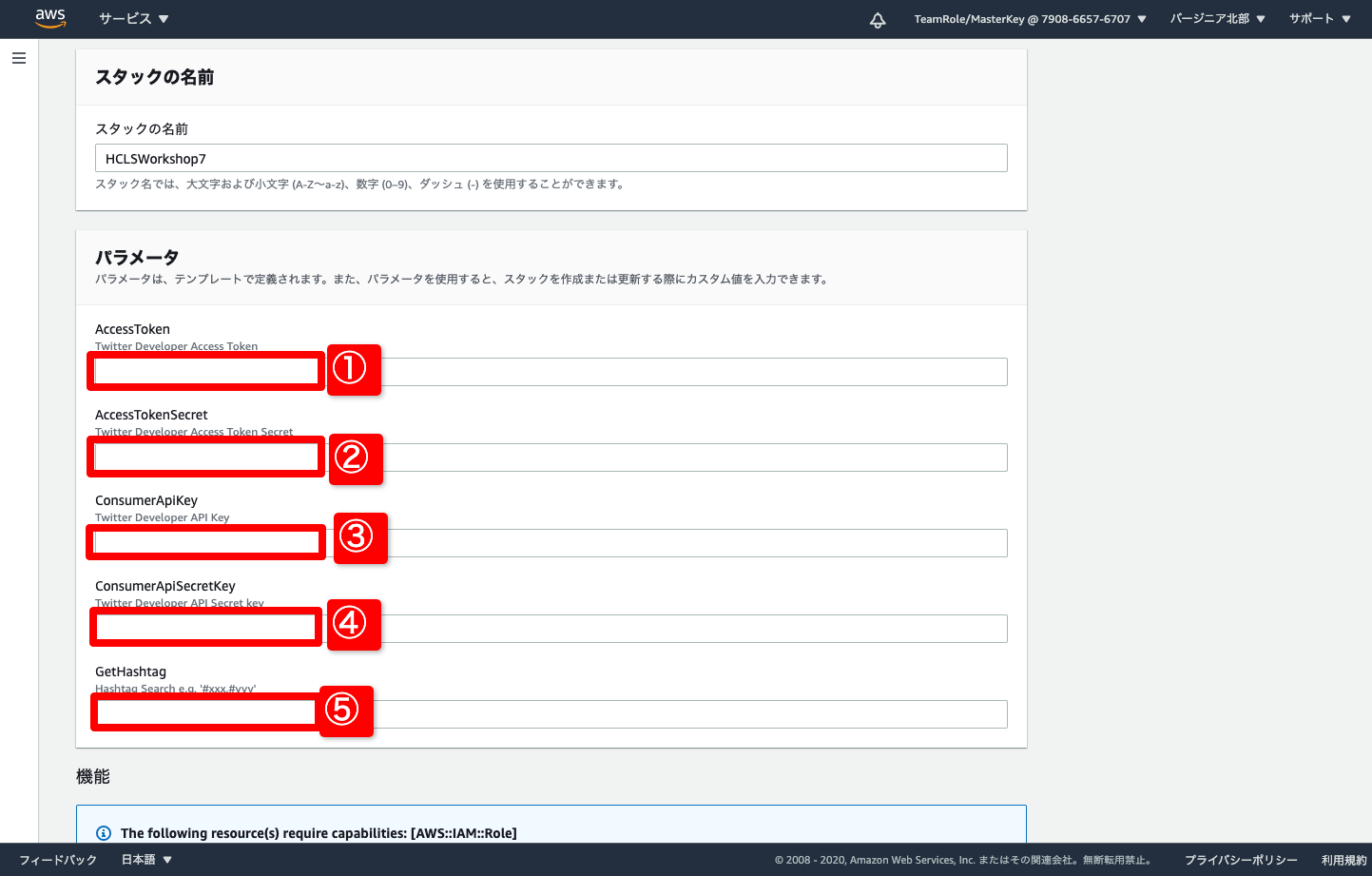
- 環境の設定に必要なパラメータを入力します 4つのパラメータに間違わないよう入力してください!!
- AccessToken
- 事前に用意したTwitterの Developer Access Token をコピー&ペーストする
- AccessTokenSecret
- 事前に用意したTwitterの Developer Access Token Secret をコピー&ペーストする
- ConsumuerApiKey
- 事前に用意したTwitterの Developer API Key をコピー&ペーストする
- ConsumerApiSecretKey
- 事前に用意したTwitterの Developer API Secret Key をコピー&ペーストする
- GetHashtag
- 今回のハンズオンで取得したいハッシュタグを記入する。 複数のハッシュタグを指定するにはカンマで区切る
- 文法としては、#検索したいキーワード1つ目,(カンマ)検索したいキーワード2つ目となります
- # と , は、半角 です
- 例: #抗がん剤,#副作用
- 任意ハッシュタグを指定できます。上記のキーワードが少しセンシティブな場合は、別なキーワードに置き換えていただいても大丈夫です
- その場合、こちらのTwitterの検索画面(例えば#新型コロナ)で、引っかかるかを事前に確認してください
- AccessToken
- 画面最下部までスクロールします
- チェックボックスを入れます
- スタックの作成 をクリック
- ステータスが CREATE_IN_PROGRESS となり作成が開始されます
- 作成完了まで5−7分程度かかります
- 作成完了になるとステータスが CREATE_COMPLETE になります
これで構築自体は完了です。
各サービスがきちんと構築されたか、各サービスの動作や内容を理解しながらチェックしていきましょう!
それでは、最初にLambdの設定について確認していきます(特に設定する箇所はありません。手順に従って確認だけ行います)
- 確認する箇所は下記となります
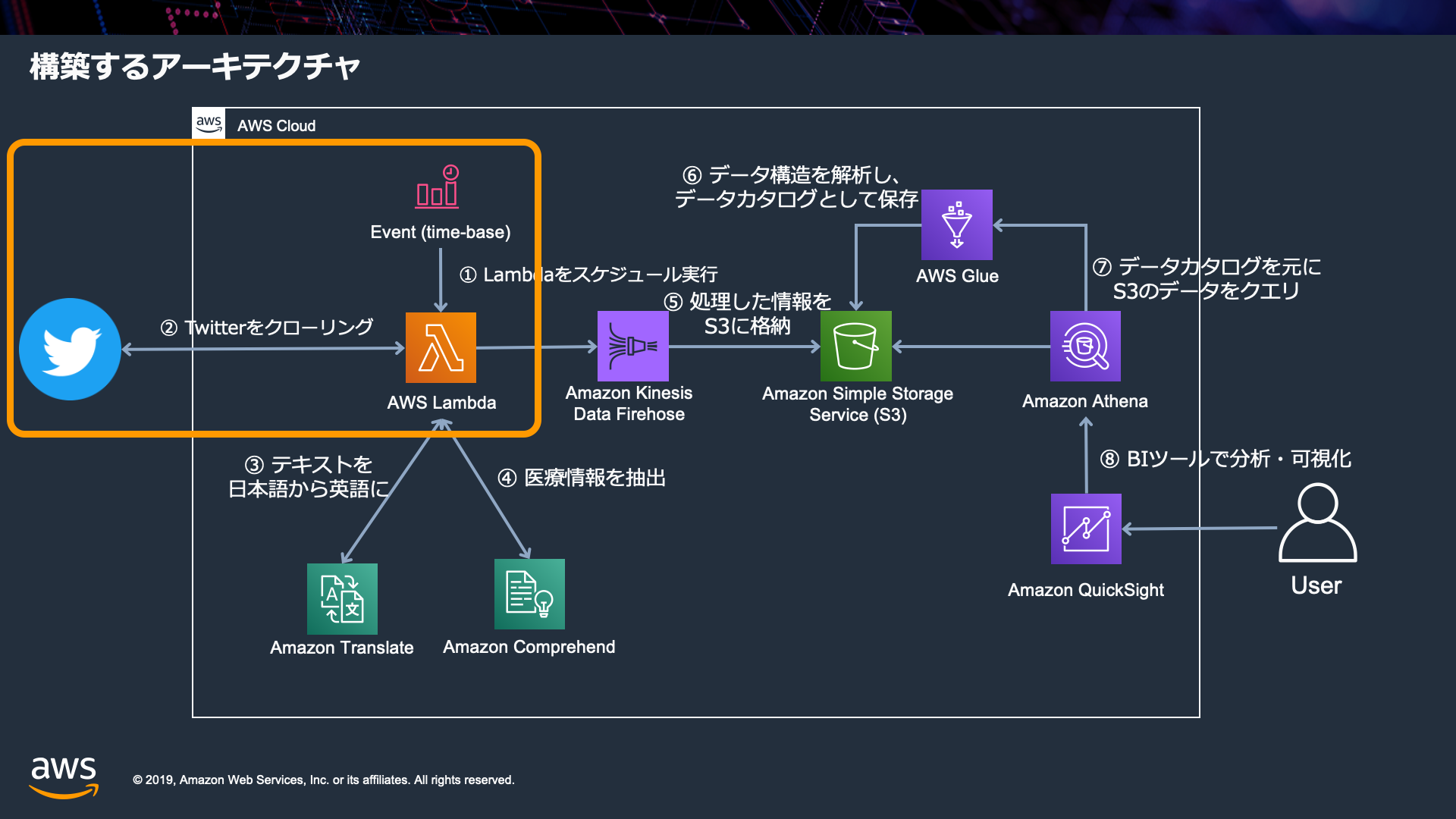
- また、下記のポイントに注目して理解しましょう
- Lambdaが何をしているか?を確認
- Lambdaは何がトリガーで実行されているのか?
- Lambda上で動作するプログラム対して、どうやって、APIパスワードや興味があるハッシュタグを渡しているのか?
- Lambda が実際に定期的にトリガーされているか?
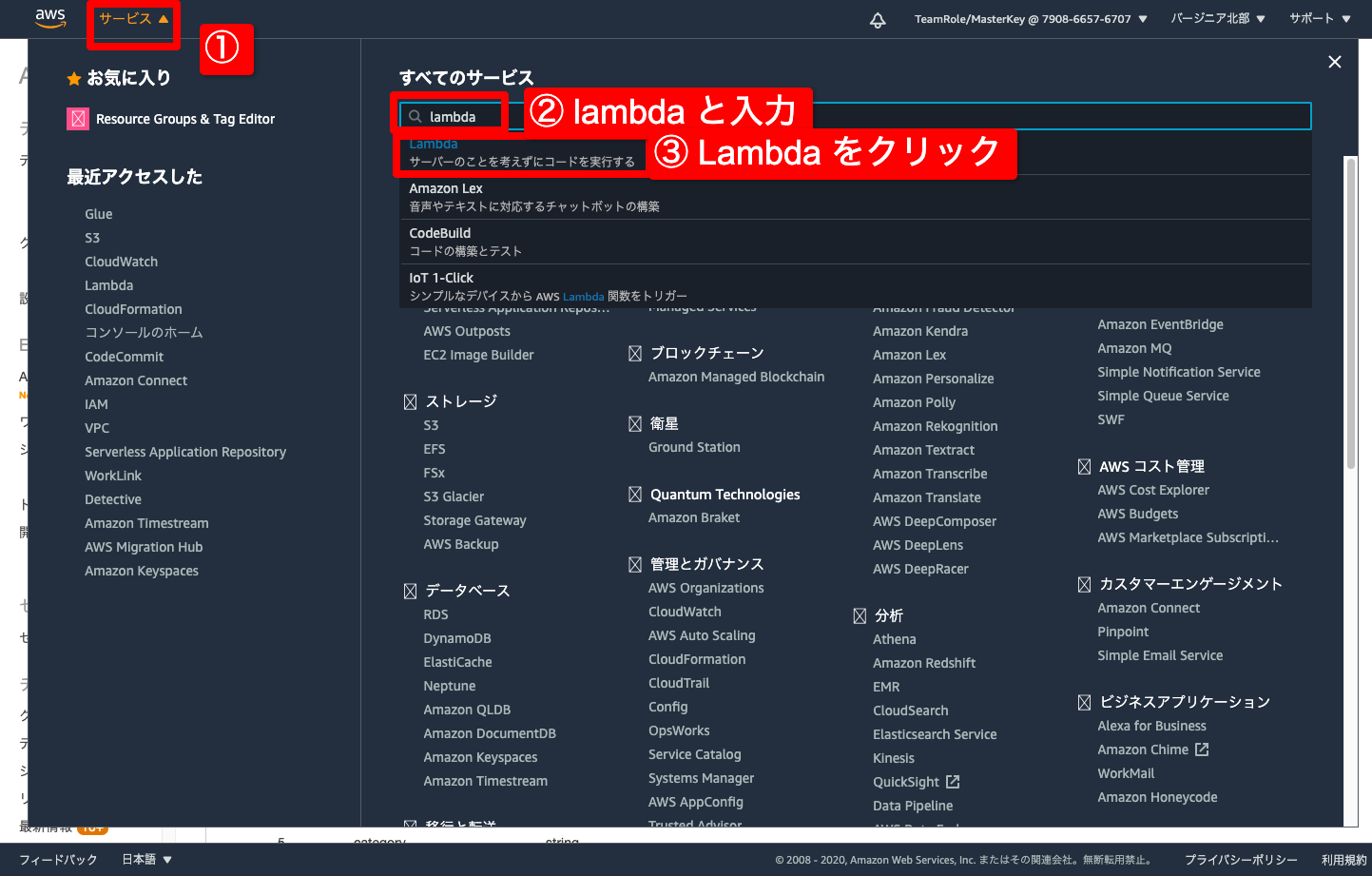
- 画面左上のサービスをクリック
- サービスの検索窓に lambda と入力
- Lambda をクリック
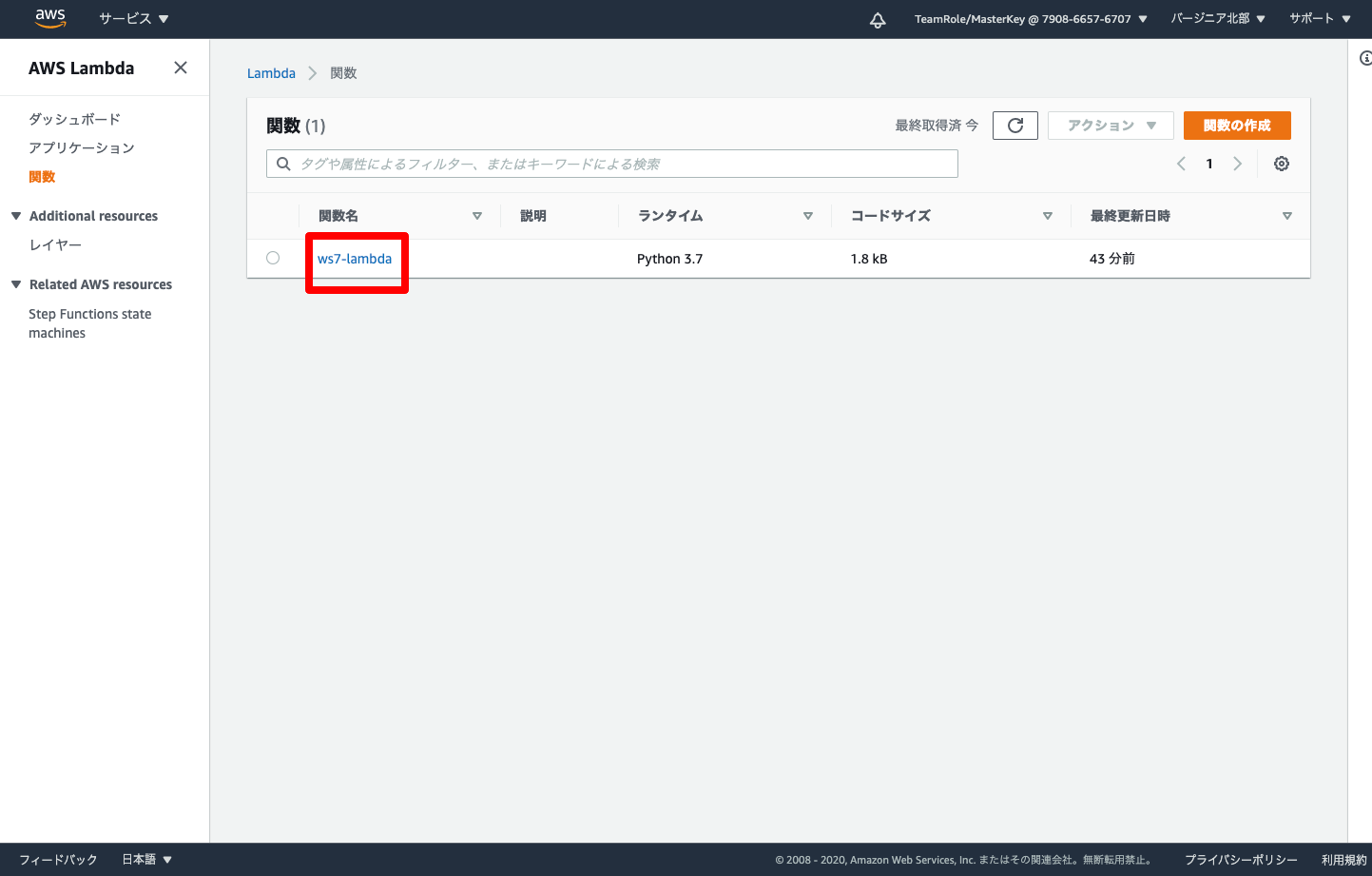
- 設定されたLambdaをクリックします
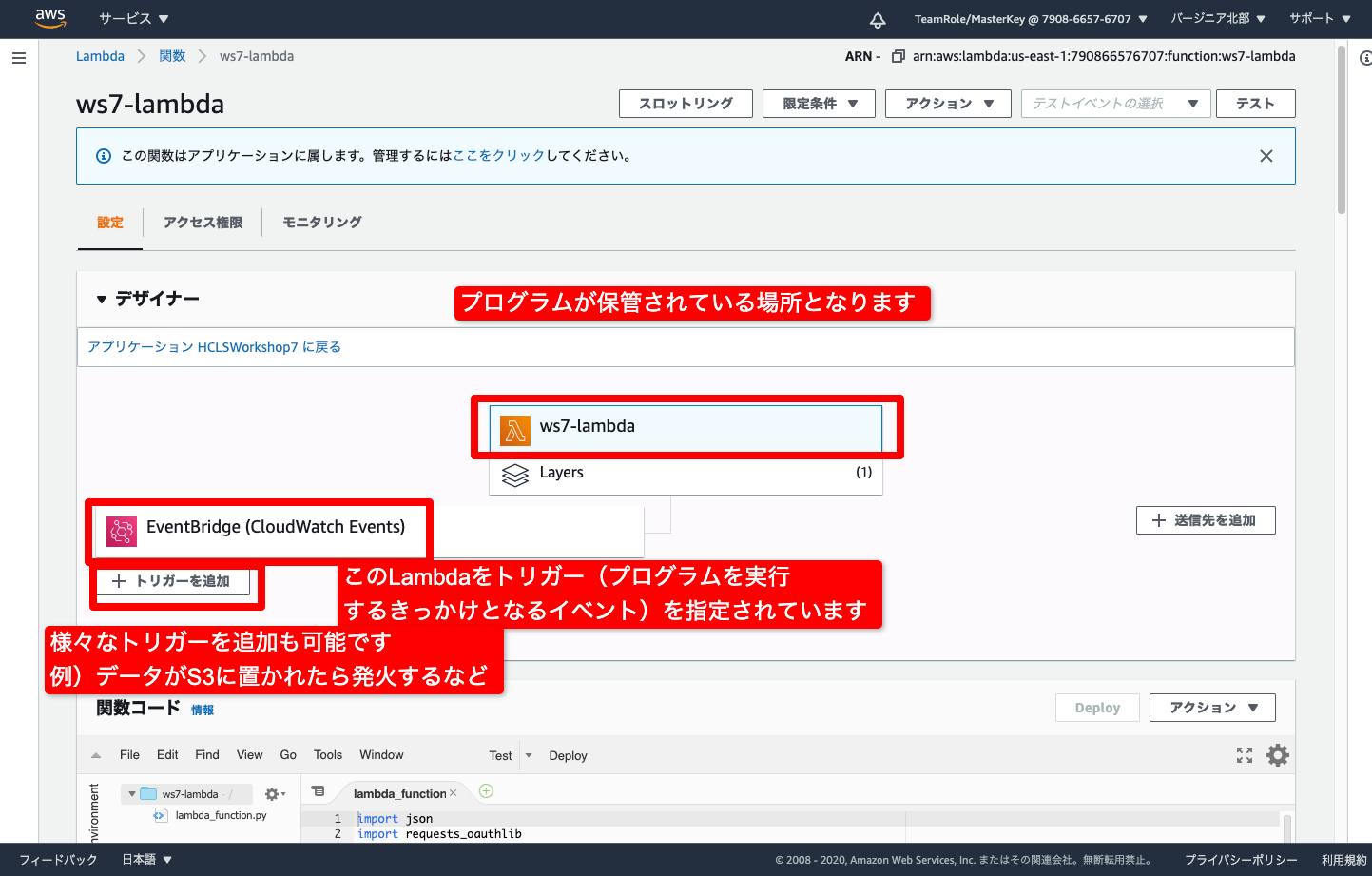
- Lambdaの設定が確認できます
- ここでトリガー(このLambda/プログラムが呼び出されるタイミング)を設定できます
- 他にもトリガーは追加設定が可能です
- Lambdaに設定されているプログラムが確認できます
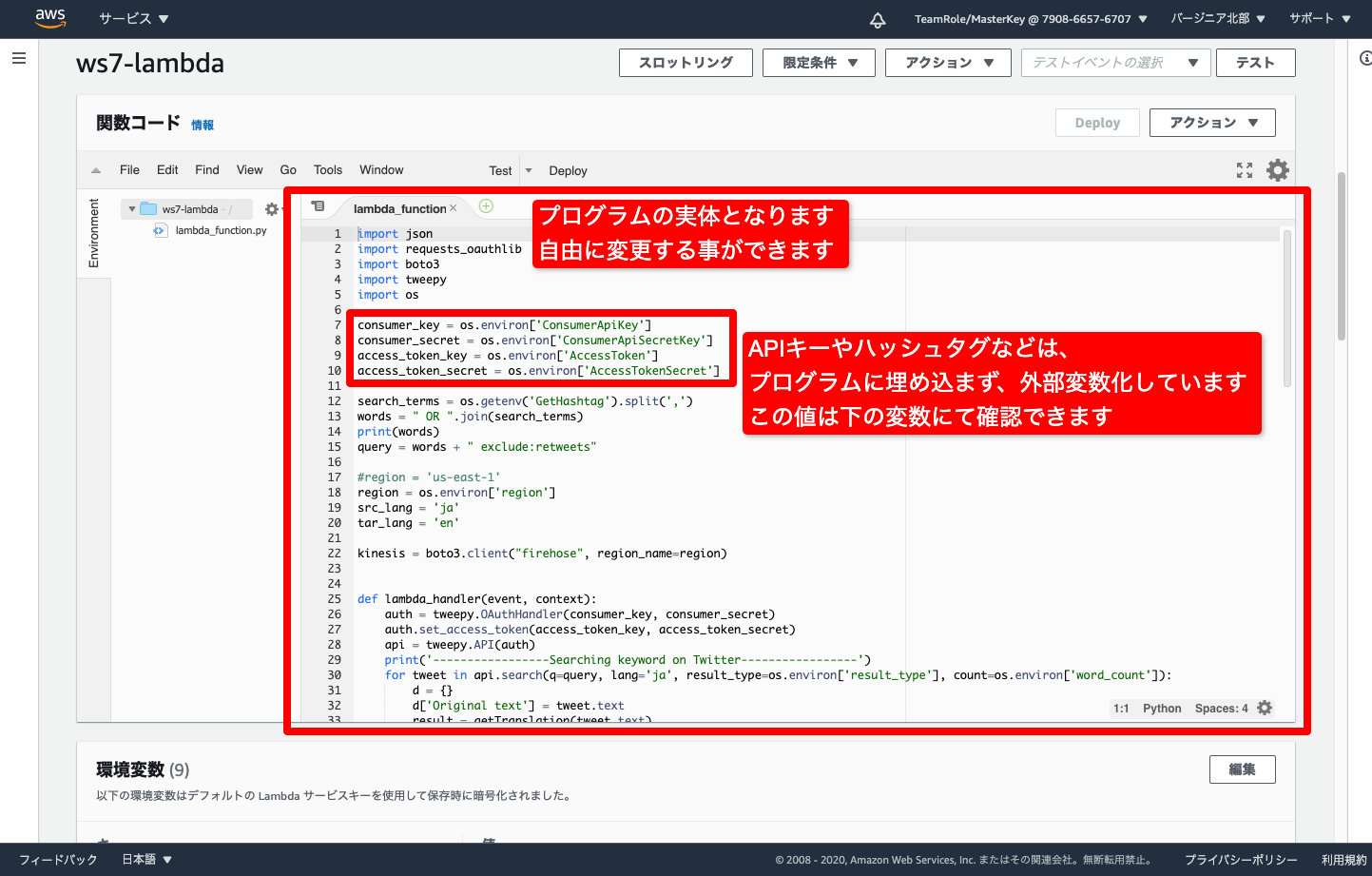
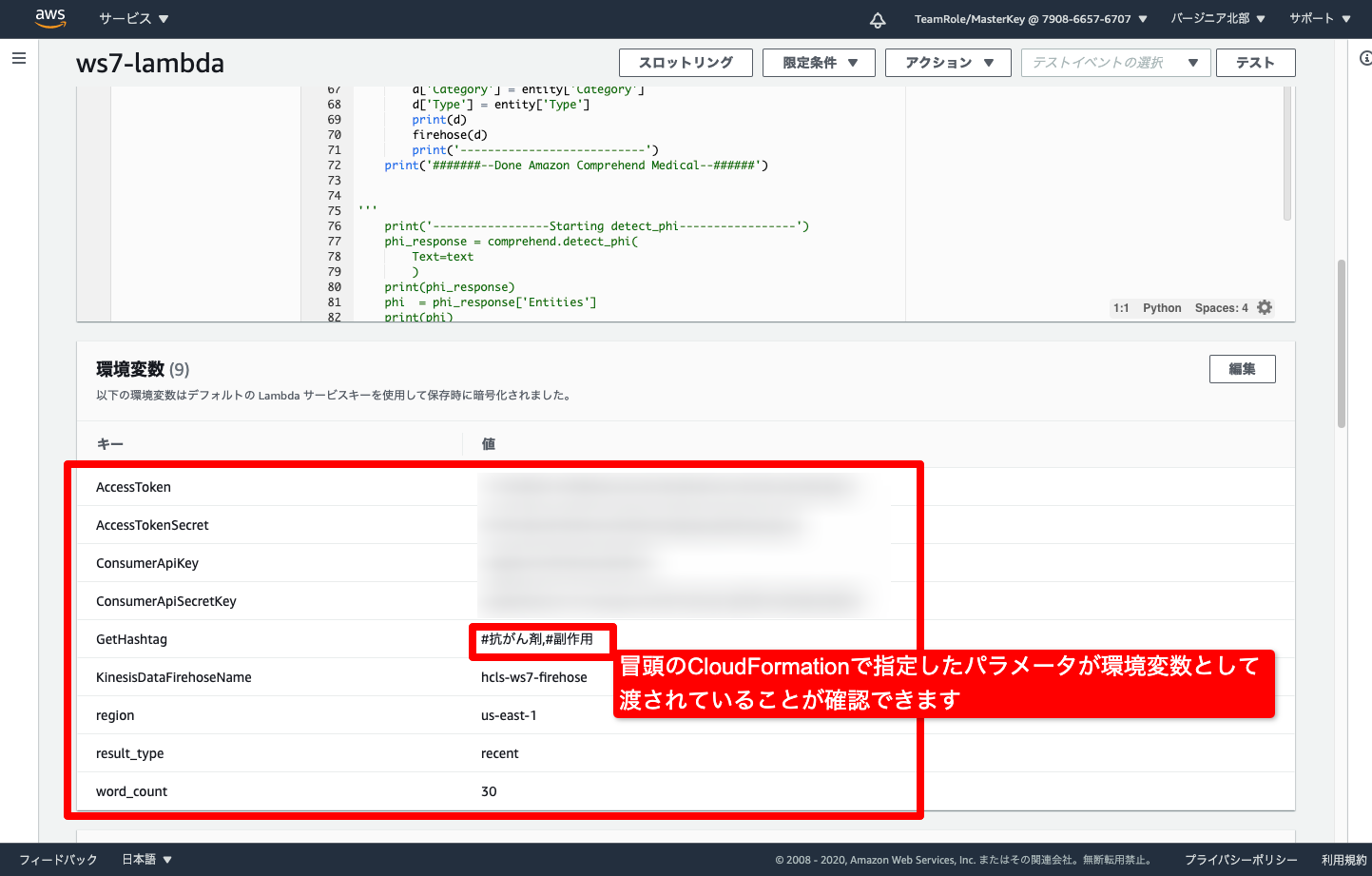
- Lambdaに渡す設定値がプログラムとは別に環境変数で渡しています
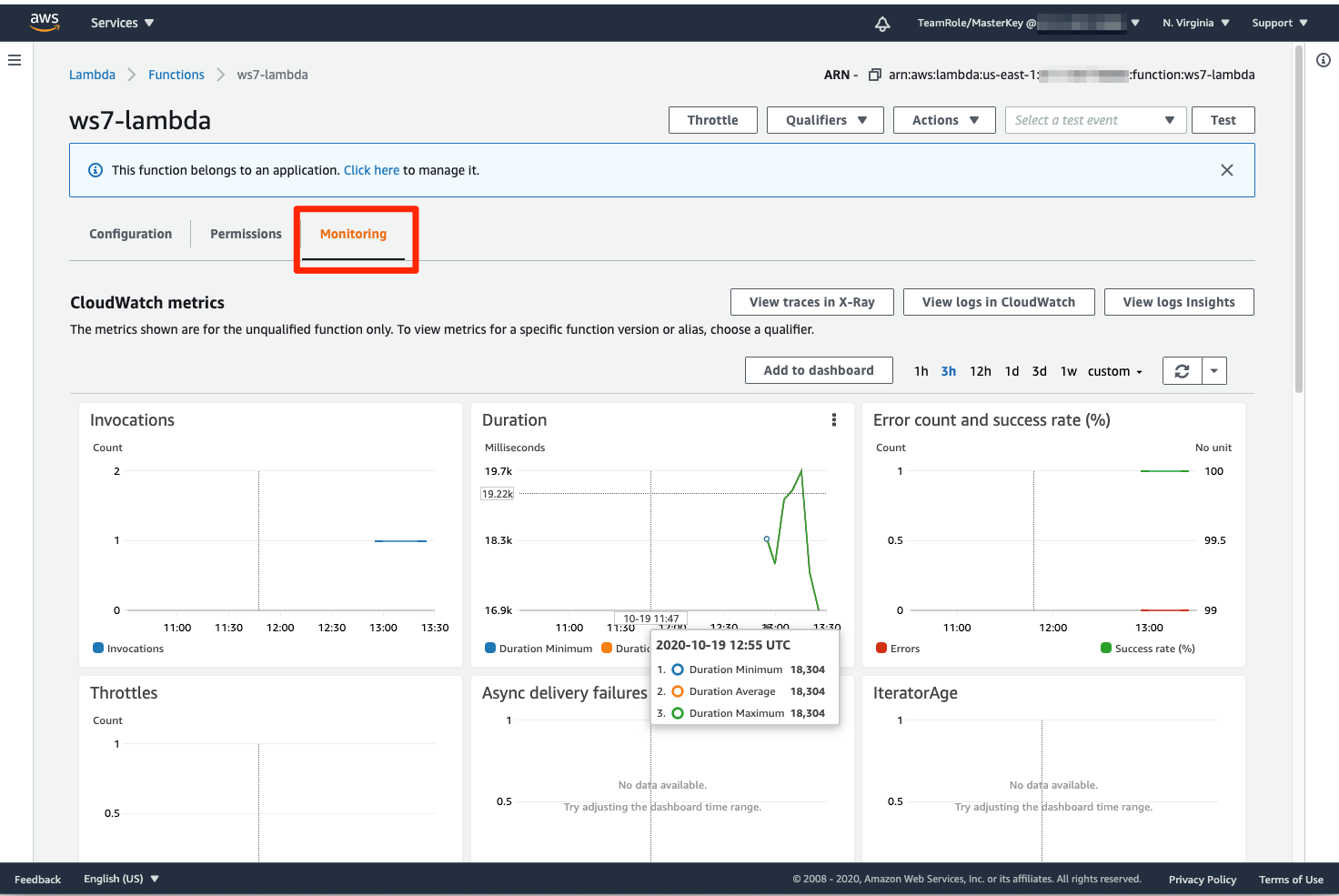
- Lambda の「モニタリング」タブをクリック
- 定期的に Lambda が実行され、実行が正常終了していることが確認できます
次に、最初にS3にデータが正常に取得されているかを確認します(特に設定する箇所はありません。手順に従って確認だけ行います)
- 確認する箇所は下記となります
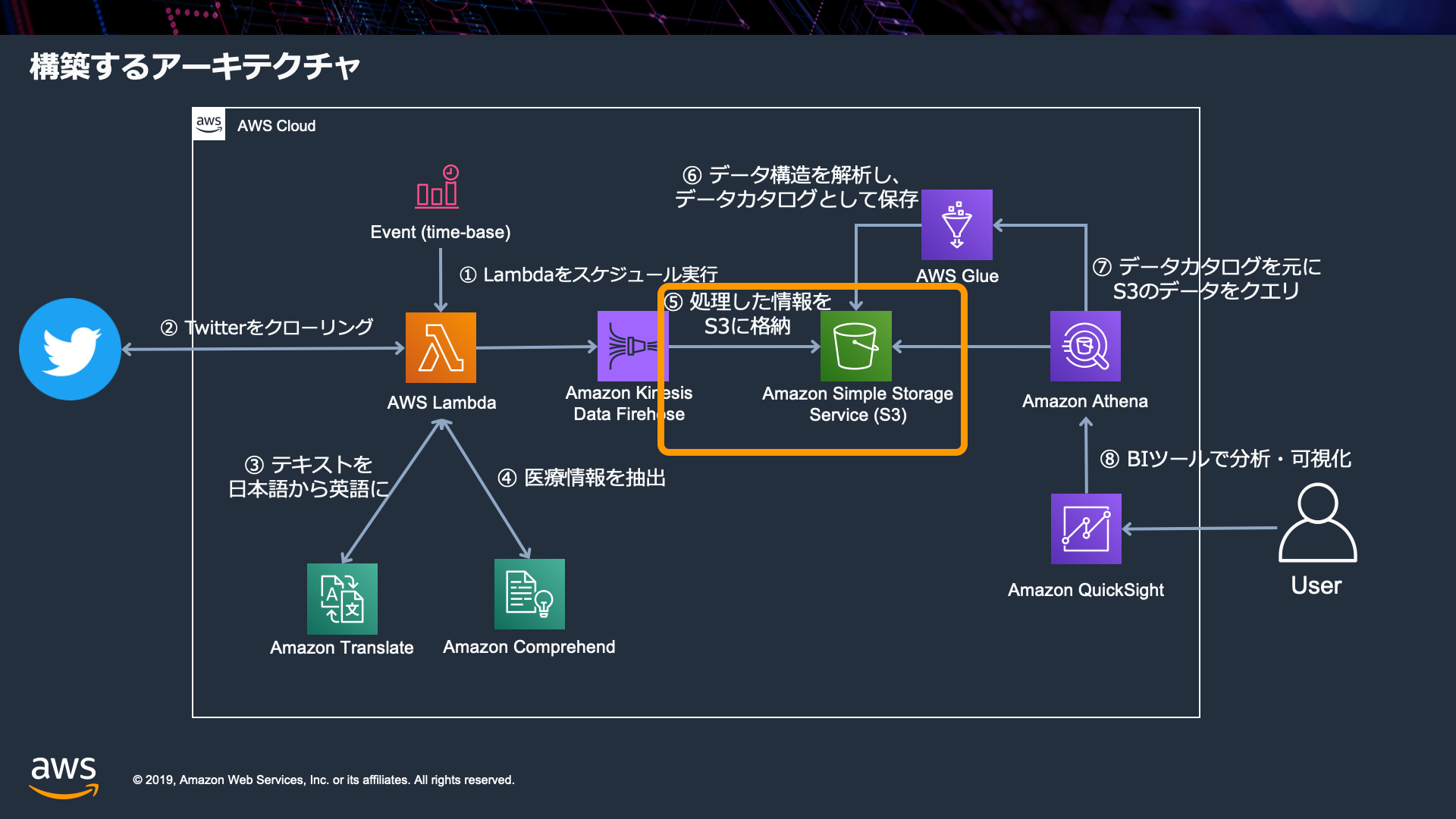
- また、下記のポイントに注目して理解しましょう
- Lambdaが置いたデータはどのような形で保管されているのか?(フォルダ構造)
- 置かれたデータはどういったフォーマットで保管されているか?
- 置かれたデータが、どのように格納されているか実際に見てみる
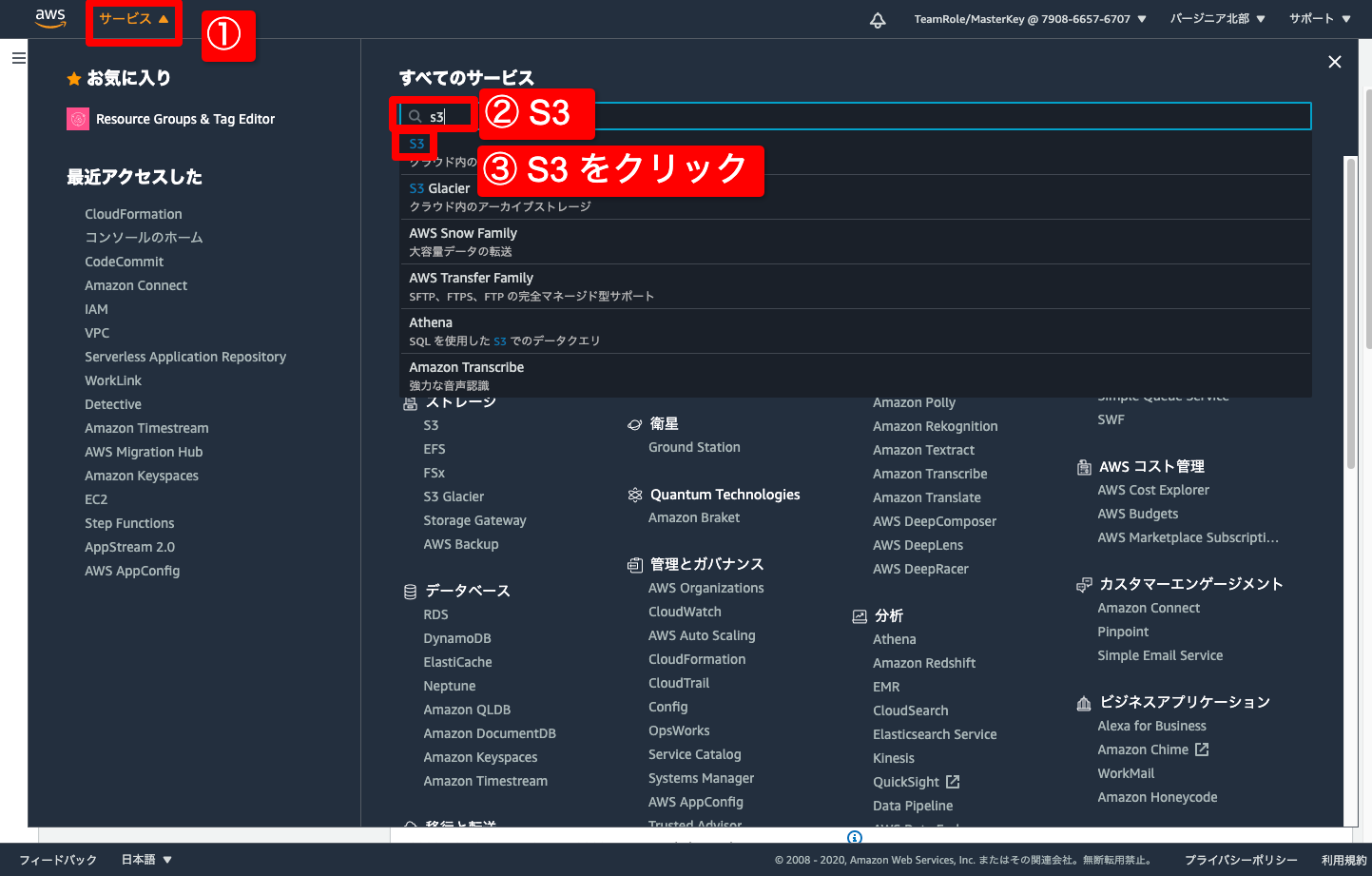
- 画面左上の サービス クリック
- サービス検索窓に S3 と入力
- S3 をクリック
- Lambdaが置いたBucket(フォルダ)が見えるので、そこをクリック
- 年(2020)、月(10月)、日(19日)、時間(02)のようにクリックしていく
- (カッコ)は例の時刻となります。ハンズオンを実行した時間に読み替えてください
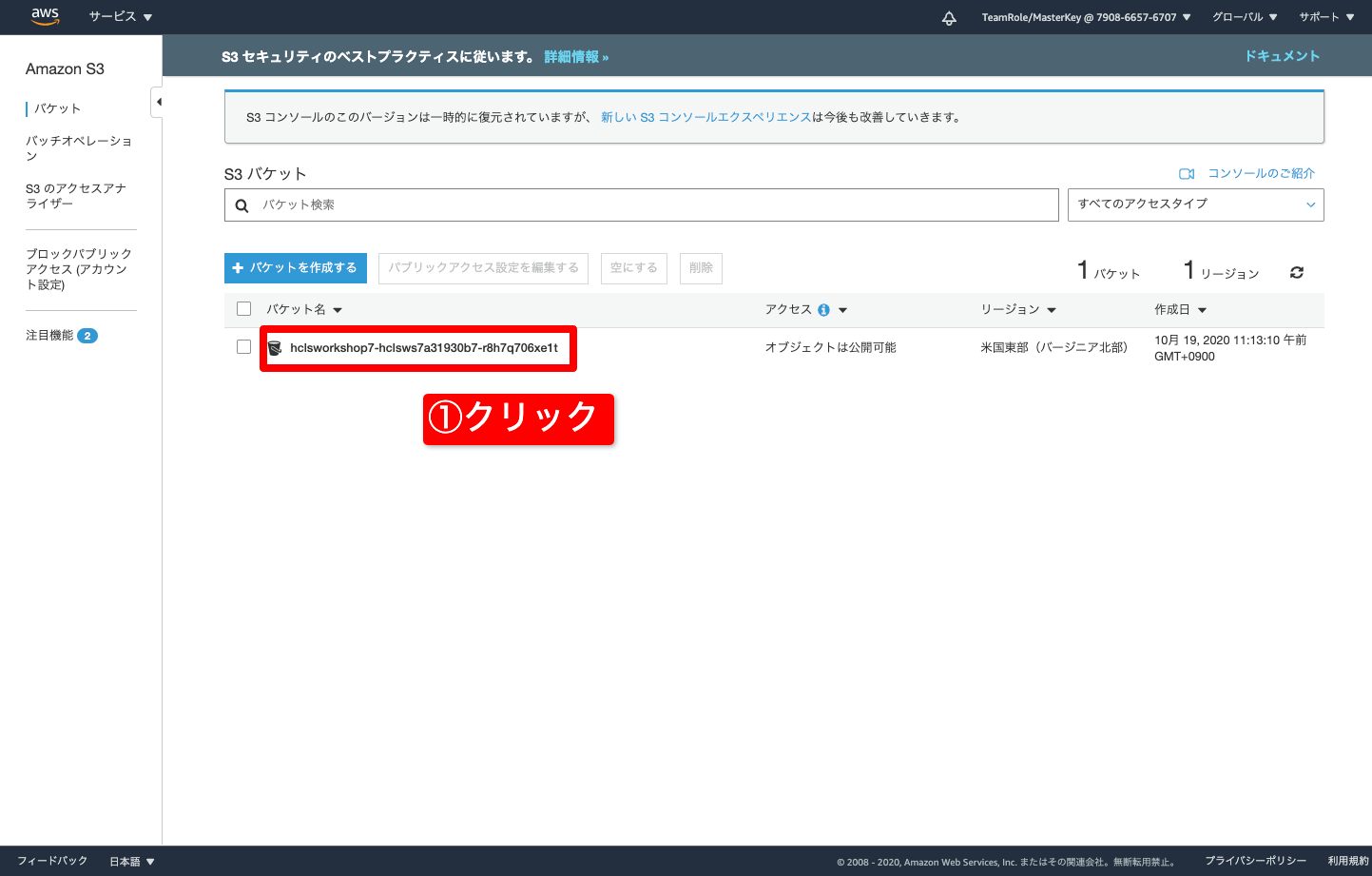
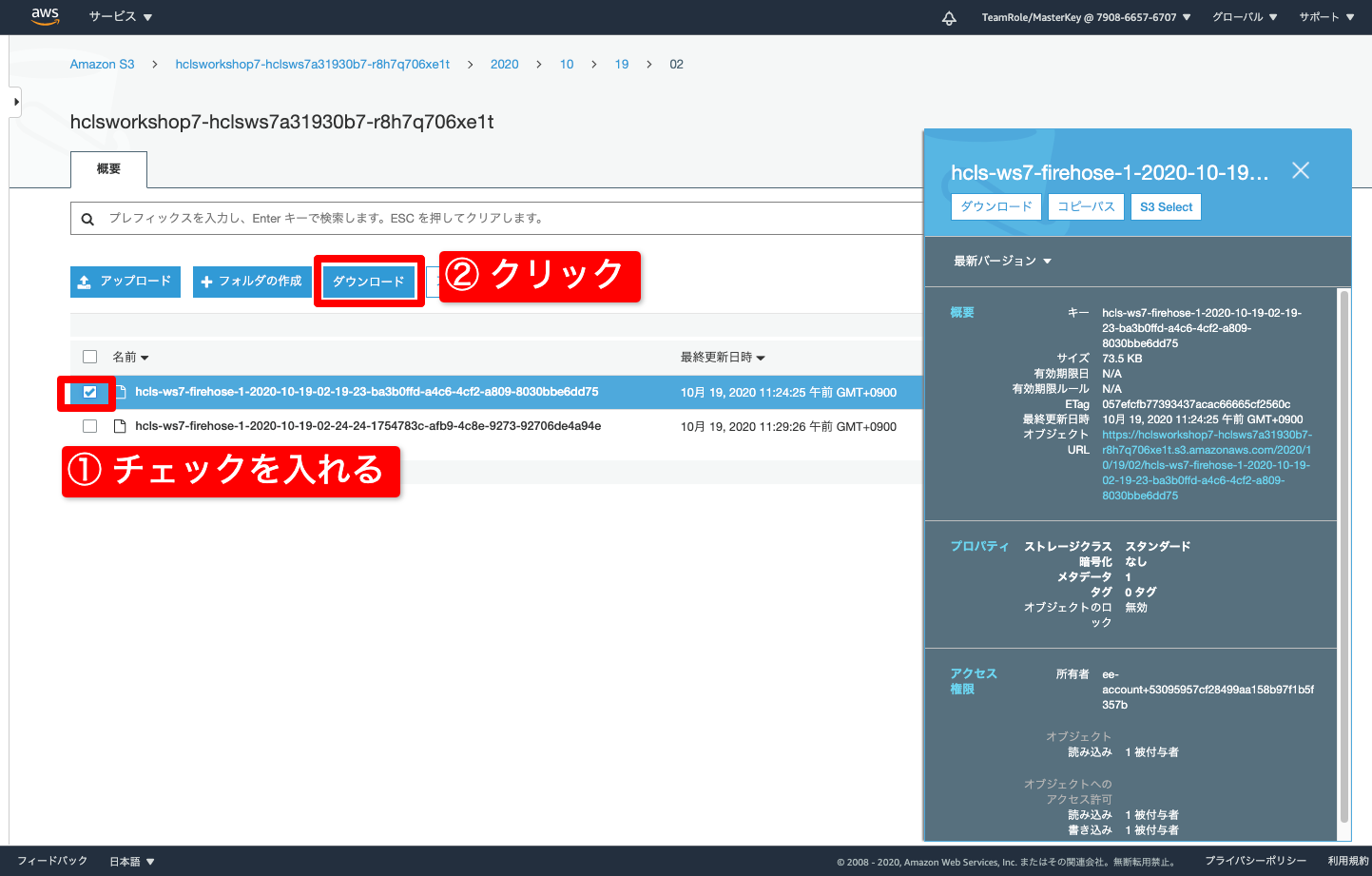
- 日時のキー(フォルダ)まで、クリックしていくと、最後にオブジェクト(ファイル)が見えるのでダウンロードしてみます
- チェックを入れる
- ダウンロード
- 時刻はUTC表記です。日本時間JSTで考える場合 +09:00 となります
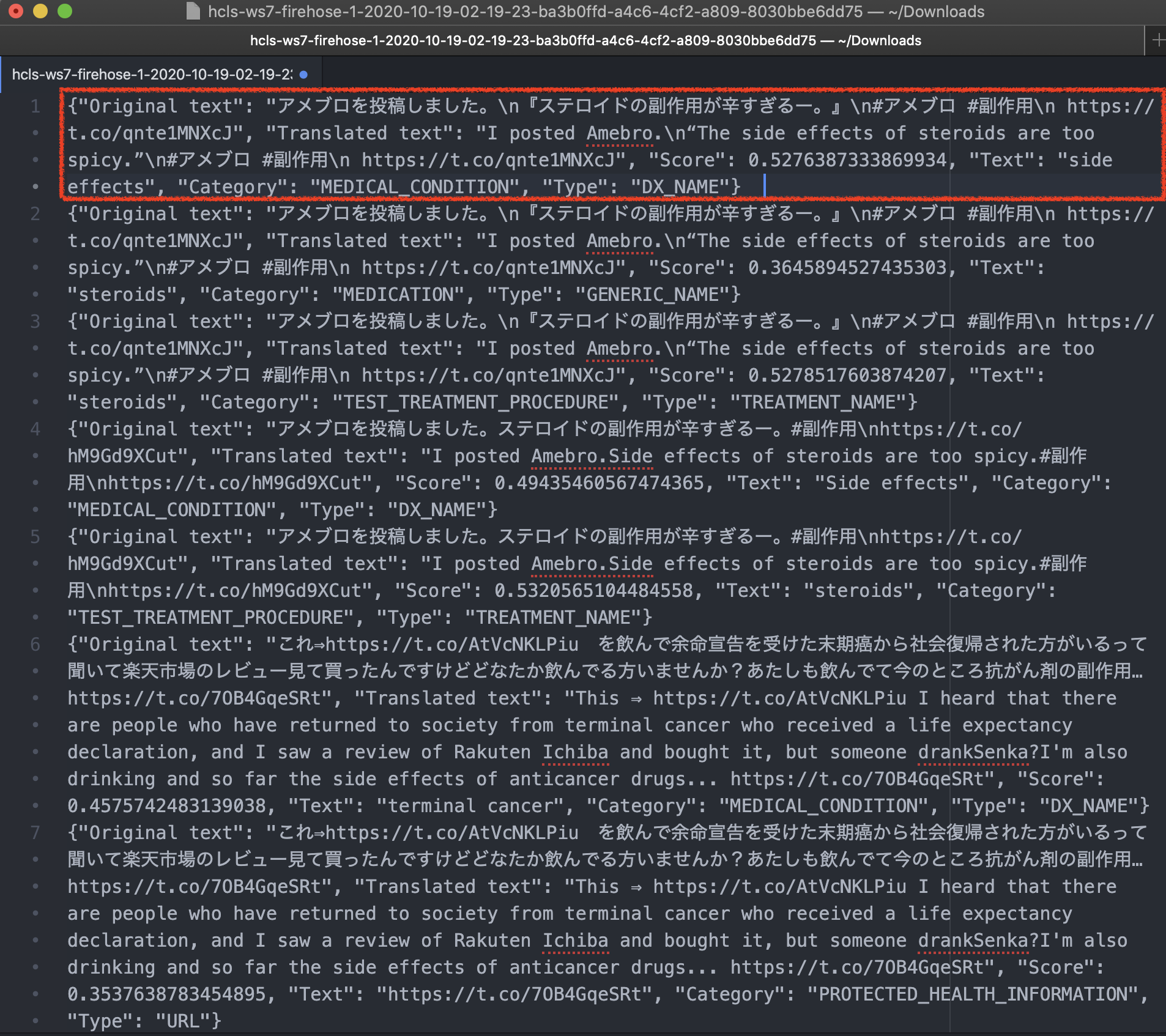
- 自端末のテキストエディタにてダウンロードしたファイルを開いてみます
- JSON形式で保管されていることがわかると思います
- より、このファイルを見やすくしたい場合は、JSON Viewerなど各種エディタをご利用ください
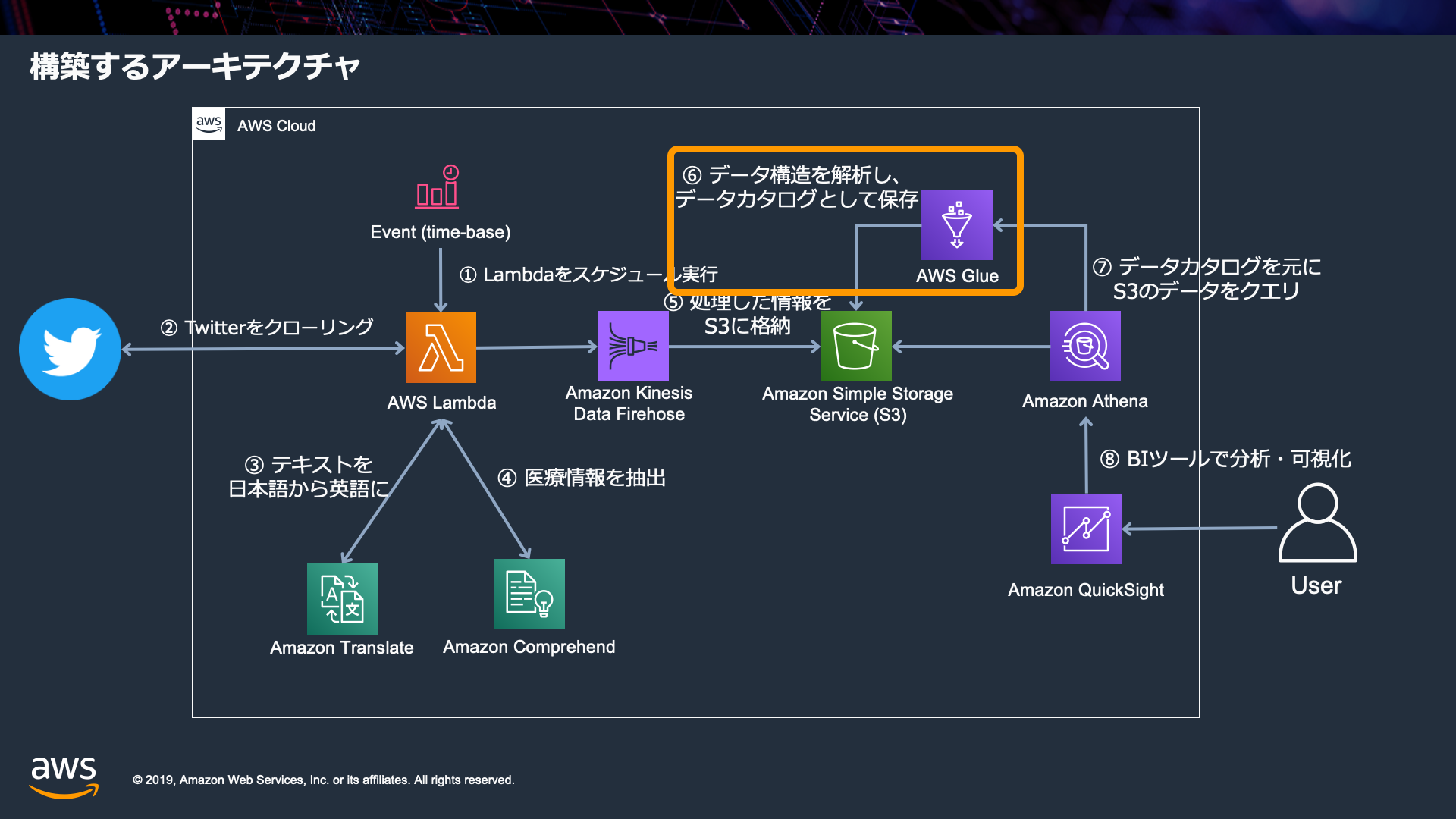
最後に、AWS Glueの設定について確認していきます(特に設定する箇所はありません。手順に従って確認だけ行います)
- 確認する箇所は下記となります
- また、下記のポイントに注目して理解しましょう
- Glueが何をしているか?を確認
- もしGlueがなかったら? どんな機能が必要ですか?
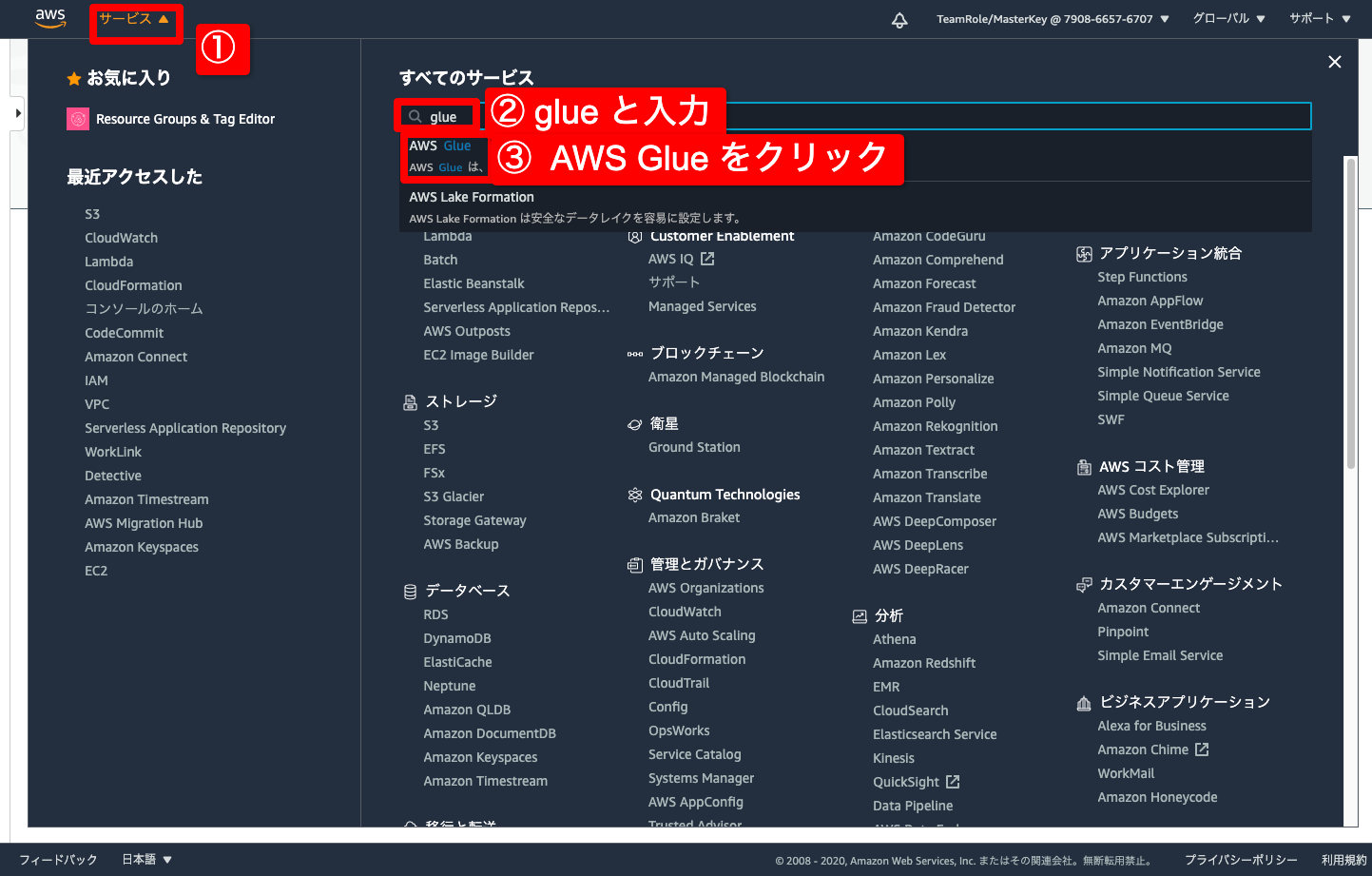
- 画面左上のサービスをクリック
- サービス検索窓に glue と入力
- AWS Glue をクリック
- テーブルの名前をクリック
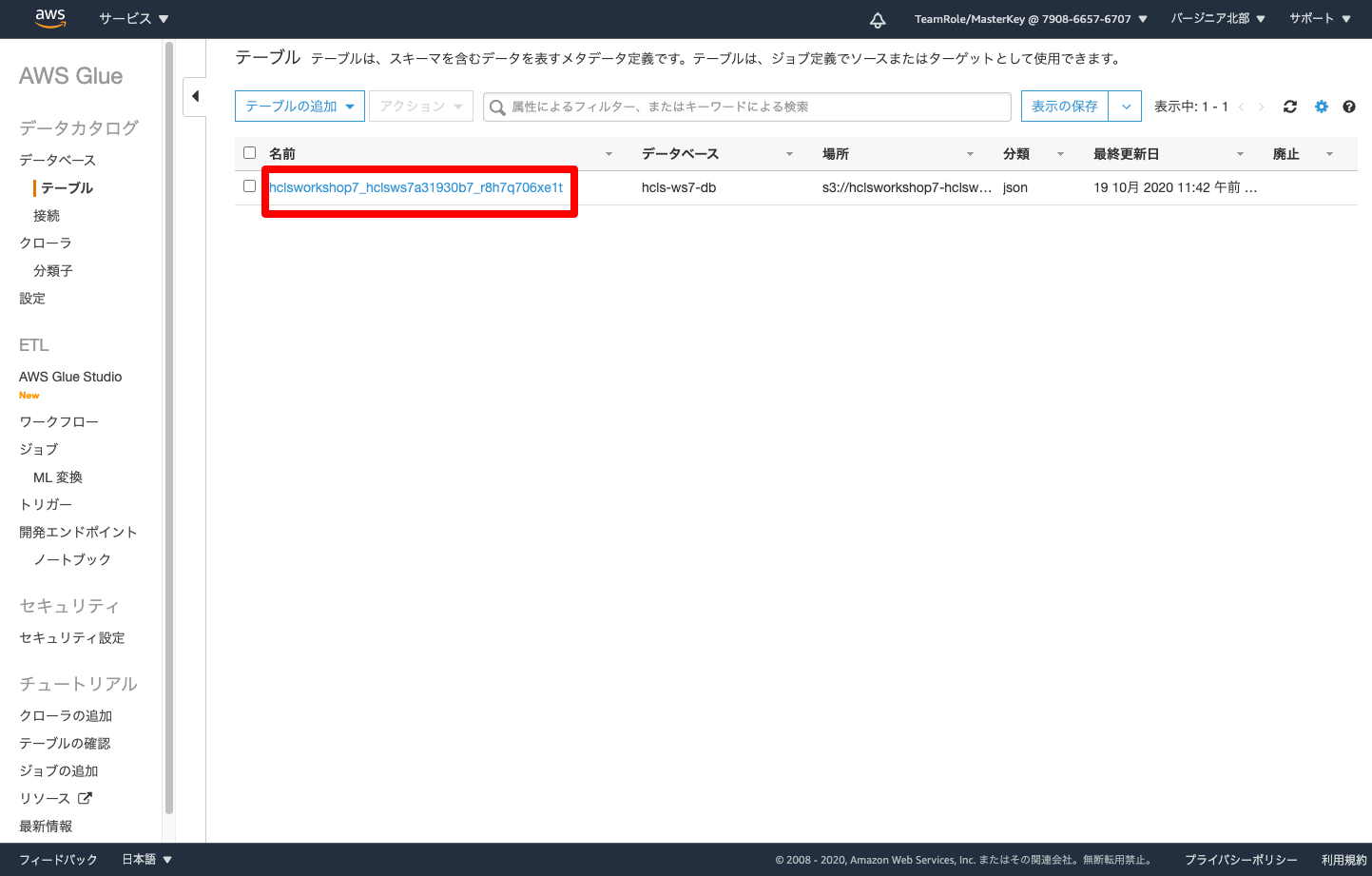
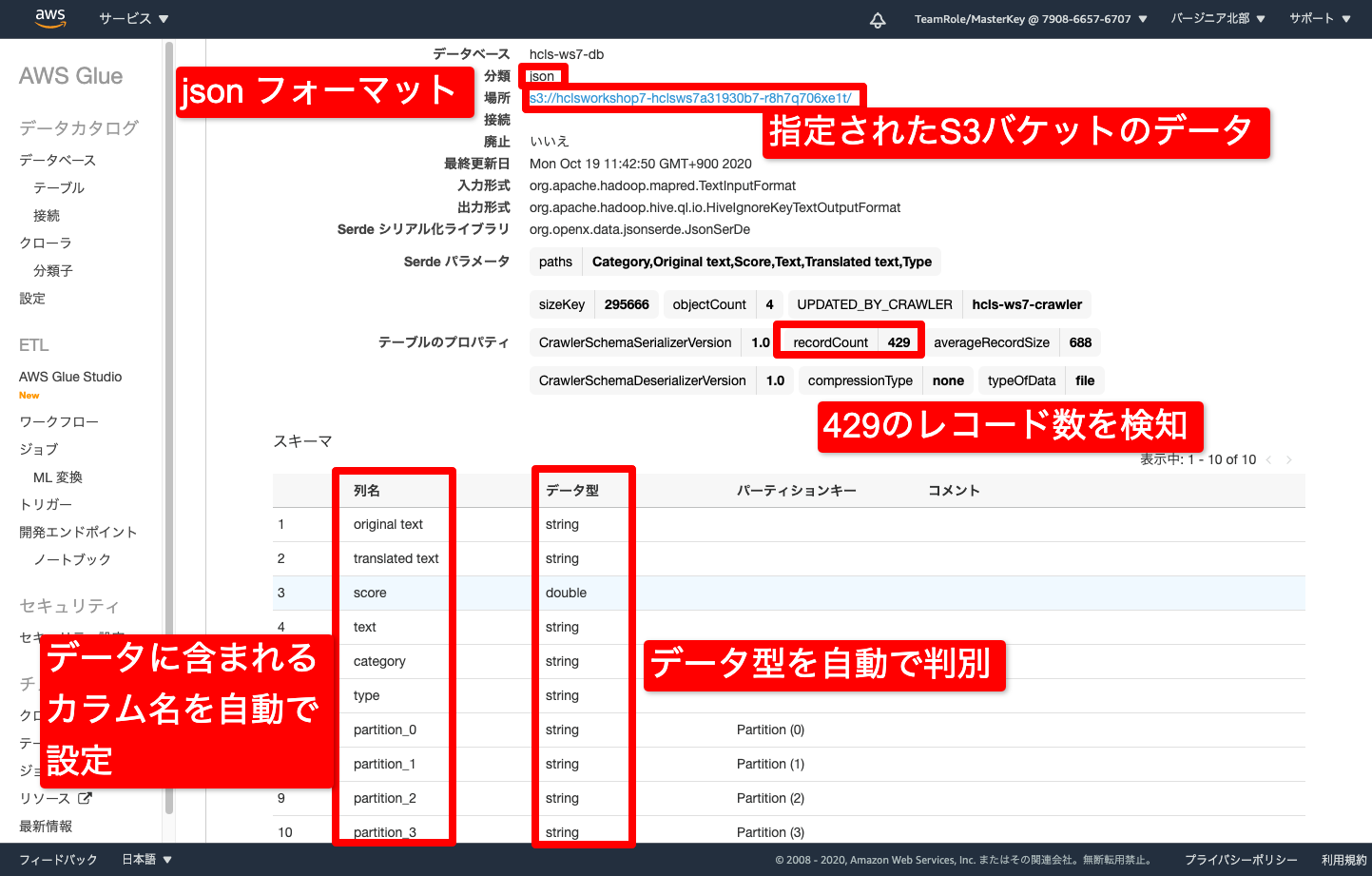
- Glue が 自動的に判別、収集した情報を確認します
- s3の場所を指定するだけで、下記の情報を自動的に集めます
- S3のバケット構造(YYYY/MM/DD)を認識して収集
- JSON形式であることを認識
- JSONを読み解き、列やデータ型を自動で設定
- レコードの数
- s3の場所を指定するだけで、下記の情報を自動的に集めます