Amazon S3の作成
AWS マネージメントコンソールにログイン
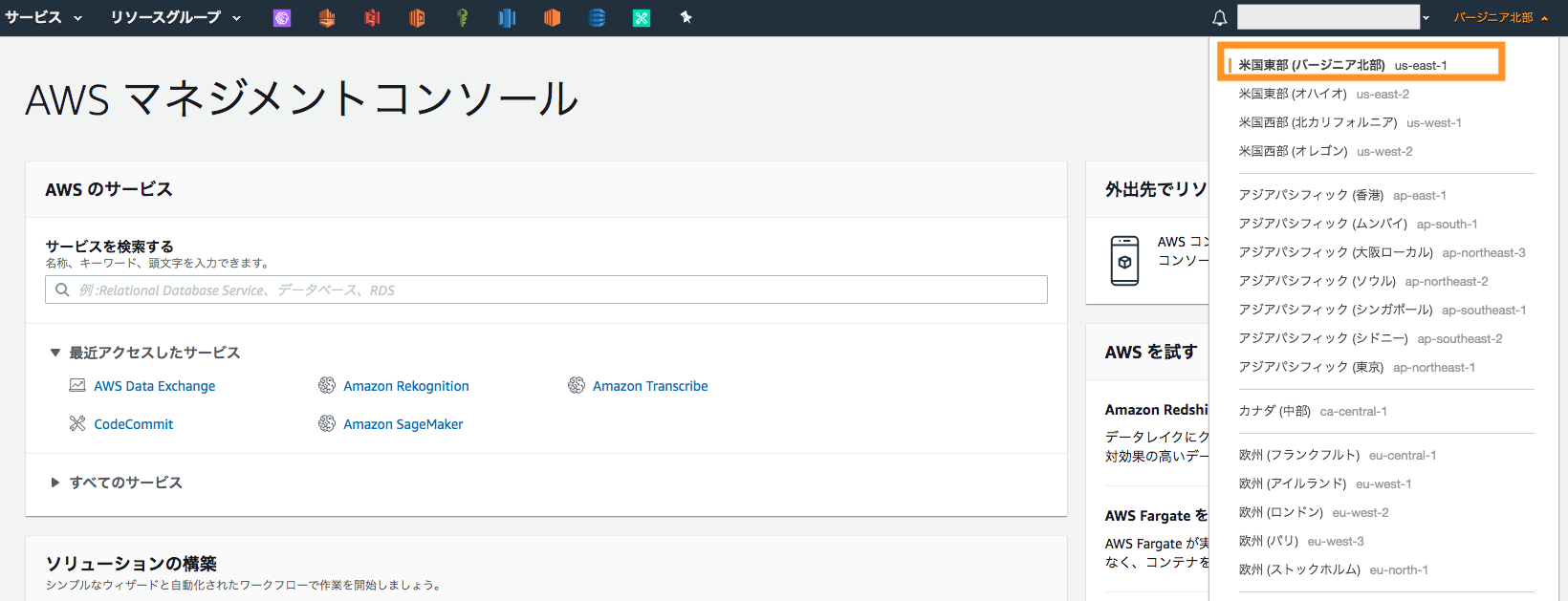
AWS マネージメントコンソールにログインし、リージョンをバージニア北部に設定。
バケットの作成
- 画面のサービス検索窓にて「S3」と入力し、S3 のページに移動
- ここでは2つのバケット(ディレクトリのようなもの)を作成します
- 1つは、Twitterをクローラし、収集できたTweetデータの保存先として
- もう1つは、クローラのプログラム本体の置き場として
- ここでは2つのバケット(ディレクトリのようなもの)を作成します
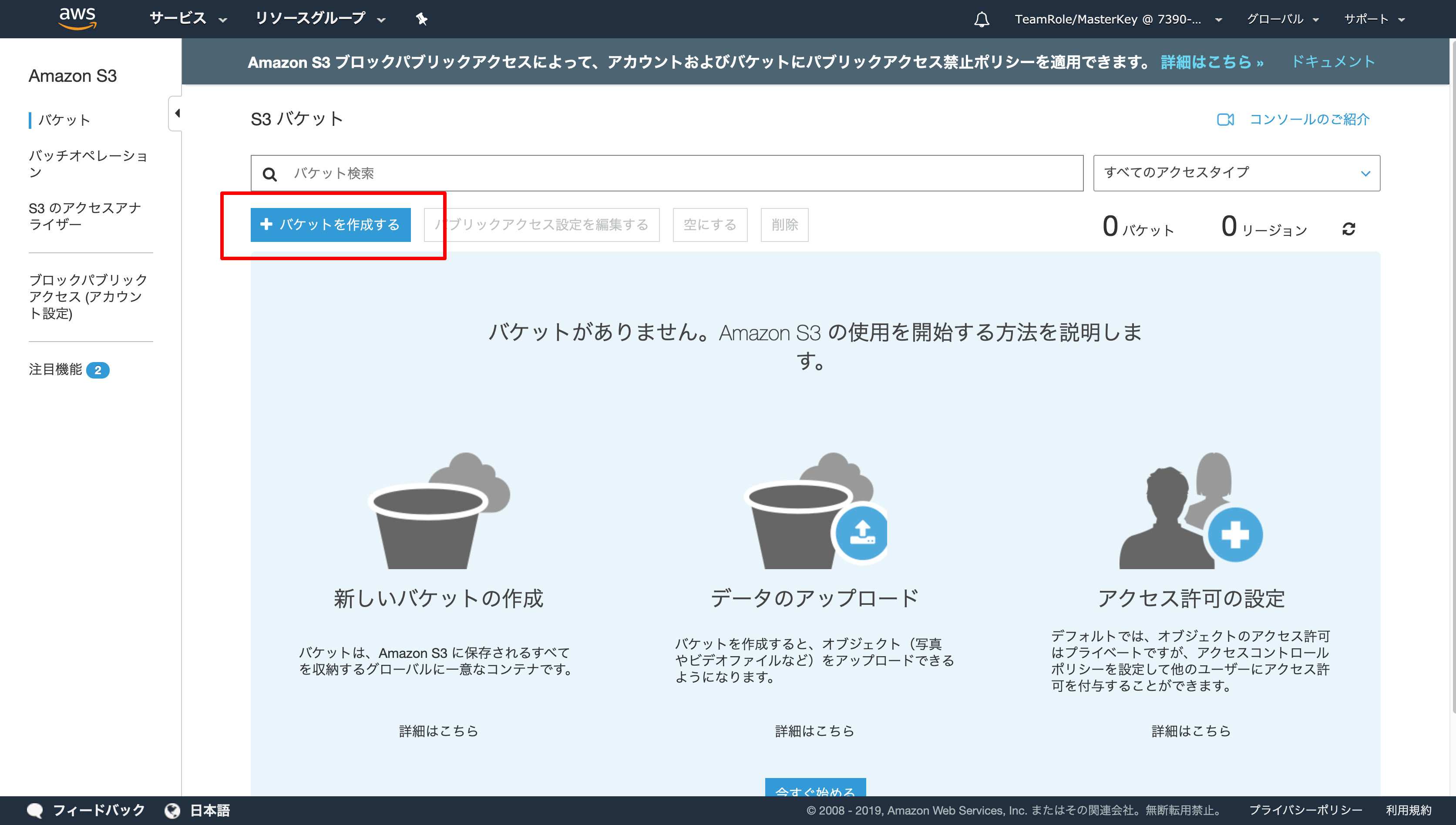
- S3 のページが表示されるので画面左上、 [バケットを作成する] を選択して設定のポップアップを開く
1つ目のバケット(Twitterをクローラし、収集できたTweetデータの保存先)を作成します
- 下記設定を行い、作成をクリック
- バケット名に任意の名前(e.g.yyyymmdd-handson7-username)
- リージョンを米国東部(バージニア北部)
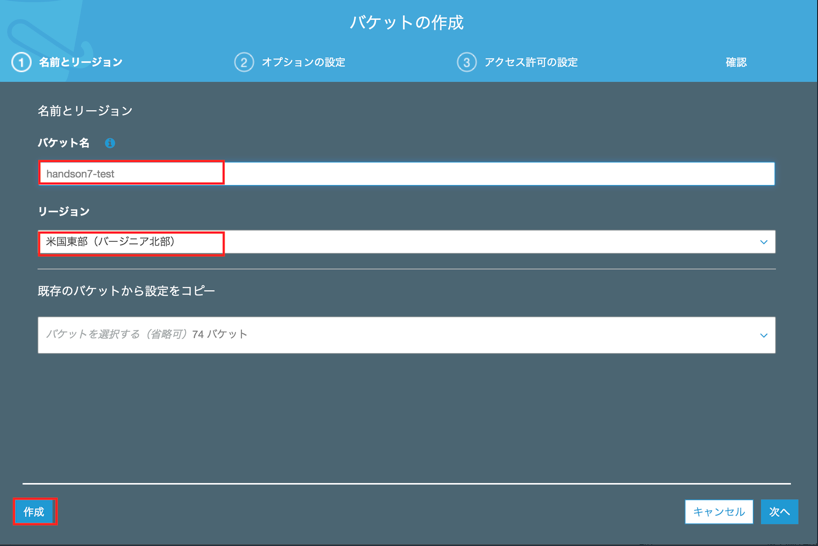
- 作成したバケット名でフィルタリングし、バージニア北部にバケットがある事を確認
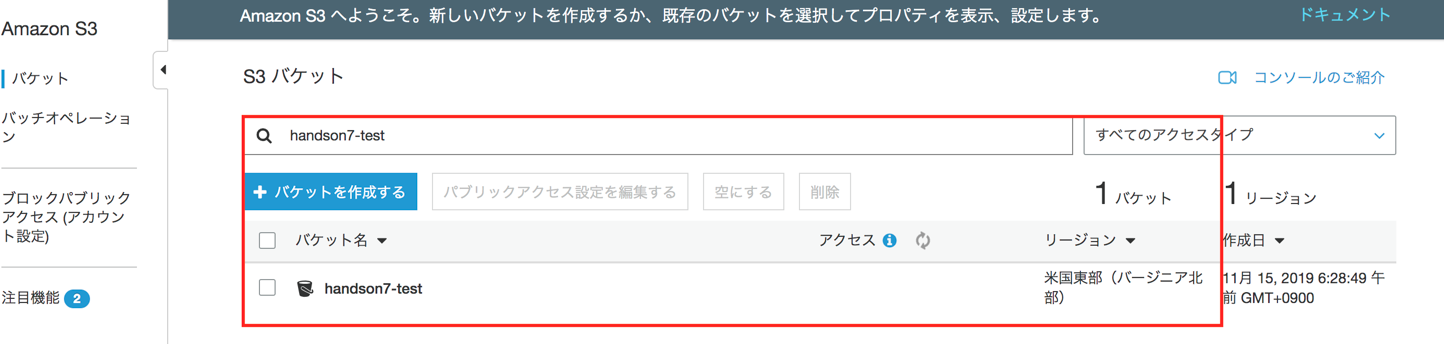
Lambdaソースコード格納用バケットを作成
- 同様にして、2つ目のバケット(Lambdaのソースコード格納用)を作成します
- バケット名: 例)yyyymmdd-source-username
- リージョン:バージニア北部
- LambdaのプログラムをDownloadします。
- こちらのリンク(Lambdaで動かすプログラム) を右クリックして保存を選択し、自端末のデスクトップ等にダウンロード
- このプログラムはサンプルプログラムとしてAWSにて用意しました
- 様々なプログラムを書くことが出来ますが、ここでは、呼び出されるとTwitterをクロールし、収集できたTweetデータをKinesis経由でS3へ保存する動作をします
- こちらのリンク(Lambdaで動かすプログラム) を右クリックして保存を選択し、自端末のデスクトップ等にダウンロード
参考
- Lambdaのサービスについて
- サービス紹介: https://aws.amazon.com/jp/lambda/
- 利用イメージについて:こちらが分かりやすいです
UploadしたLambdaのソースコードの中身
下記はダウンロードしたソースコードの中身の説明となります。プログラムの中身についてご興味ある方は参照ください。(ソースコードを理解しなくてもハンズオンには影響しません)
### モジュールをインポート import json import requests_oauthlib import boto3 import tweepy import os ### TwitterのAPIアクセスに必要な情報をセット ### os.environを使うことにより、後ほど設定するLambdaの環境変数の値をそのまま引き継ぐことができ、パスワード等をソースコードに記載せず実行ができ、セキュアでかつ再利用がしやすくなります consumer_key=os.environ['ConsumerApiKey'] consumer_secret=os.environ['ConsumerApiSecretKey'] access_token_key=os.environ['AccessToken'] access_token_secret=os.environ['AccessTokenSecret'] ### ハッシュタグが複数ある場合のSplit処理をします search_terms=os.getenv('GetHashtag').split(',') words=" OR ".join(search_terms) print(words) query = words + " exclude:retweets" #region = 'us-east-1' region = os.environ['region'] ### 取得するTwitterの言語を日本語に設定 src_lang = 'ja' ### Comprehend Medicalが対応している英語を変換先の言語として指定 tar_lang = 'en' ### Kinesisのクライアントを呼び出す kinesis = boto3.client("firehose", region_name= region ) ### Lambdaが呼ばれたときのコード def lambda_handler(event, context): ### TwitterのAPIの認証を実施 auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token_key, access_token_secret) api = tweepy.API(auth) ### TwitterのAPIにてTweetをSearchします。 ### https://developer.twitter.com/en/docs/tweets/search/api-reference/get-search-tweets print('-----------------Searching keyword on Twitter-----------------') for tweet in api.search(q=query,lang='ja',result_type=os.environ['result_type'],count=os.environ['word_count']): d = {} d['Original text'] = tweet.text ### 取得したTweetをAmazon Translateにかけて結果を日本語から英語にします result = getTranslation(tweet.text) translate_result = result.get('TranslatedText') d['Translated text'] = translate_result print(translate_result) ### 英語にしたTweet(非構造なテキスト)をComprehend Medicalにかけて構造化します comprehend_result = comprehendmedical(translate_result,d) #print(comprehend_result) #fs = firehose(d) ### ↑ 検索できたTweetの分だけ反復処理して、終わったらLambdaは終了(消滅)します ### 以下は、TranslateやComprehend Medicalなどの呼び出す関数の定義 def getTranslation(text): print('#######--Starting Amazon Translate--######') translate = boto3.client(service_name='translate', region_name = region, use_ssl=True) response = translate.translate_text( Text=text, SourceLanguageCode=src_lang, TargetLanguageCode=tar_lang ) print('#######--Done Amazon Translate--######') return response def comprehendmedical(text,d): print('######Starting Amazon Comprehend Medical######') comprehend = boto3.client(service_name='comprehendmedical', region_name=region) print('-----------------Starting detect_entities-----------------') entities_result = comprehend.detect_entities( Text=text ) print(entities_result) for entity in entities_result['Entities']: d['Score'] = entity['Score'] d['Text'] = entity['Text'] d['Category'] = entity['Category'] d['Type'] = entity['Type'] print(d) firehose(d) print('---------------------------') print('#######--Done Amazon Comprehend Medical--######') ''' print('-----------------Starting detect_phi-----------------') phi_response = comprehend.detect_phi( Text=text ) print(phi_response) phi = phi_response['Entities'] print(phi) if phi != "[]": for response in phi: print('Detected PHI', response) #return response ''' def firehose(d): print('######--Starting Amazon Kinesis Data Firehose--######') print(d) response = kinesis.put_record( #DeliveryStreamName='twitterAPI', DeliveryStreamName=os.environ['KinesisDataFirehoseName'], Record={ 'Data': json.dumps(d,ensure_ascii=False) } ) print('######--Done Amazon Kinesis Data Firehose--######') return response
先程DownloadしたファイルをUploadします
アップロードを選択
 ファイルを追加を選択します
ファイルを追加を選択します
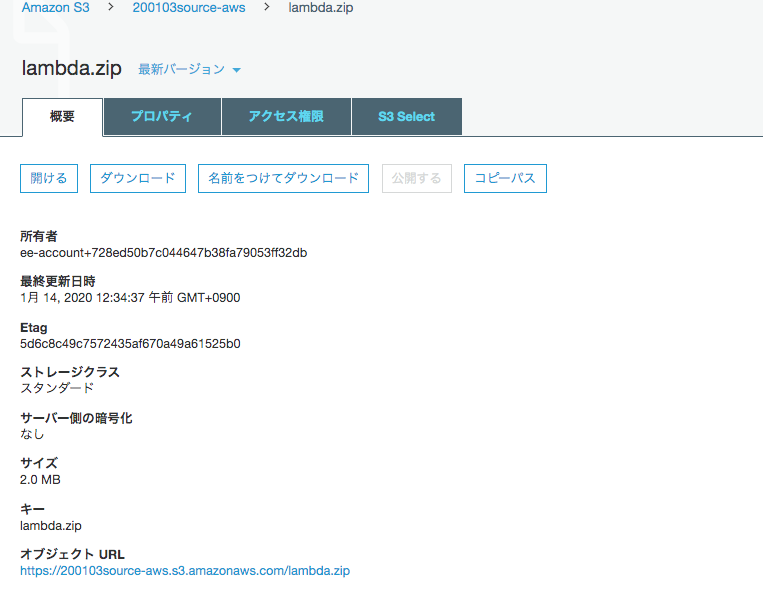
 先程ダウンロードした、 lambda.zip をアップロードします。
先程ダウンロードした、 lambda.zip をアップロードします。
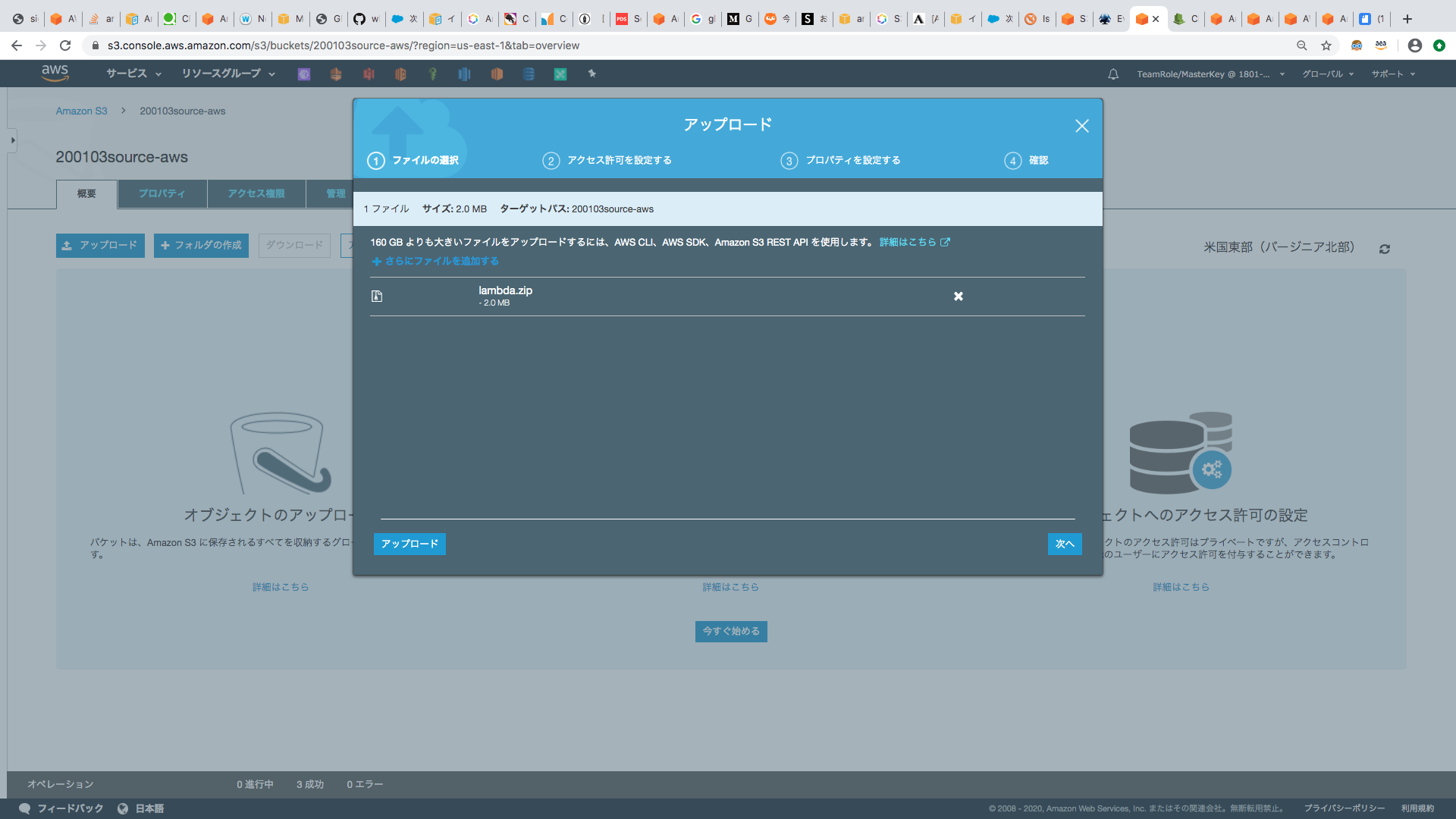
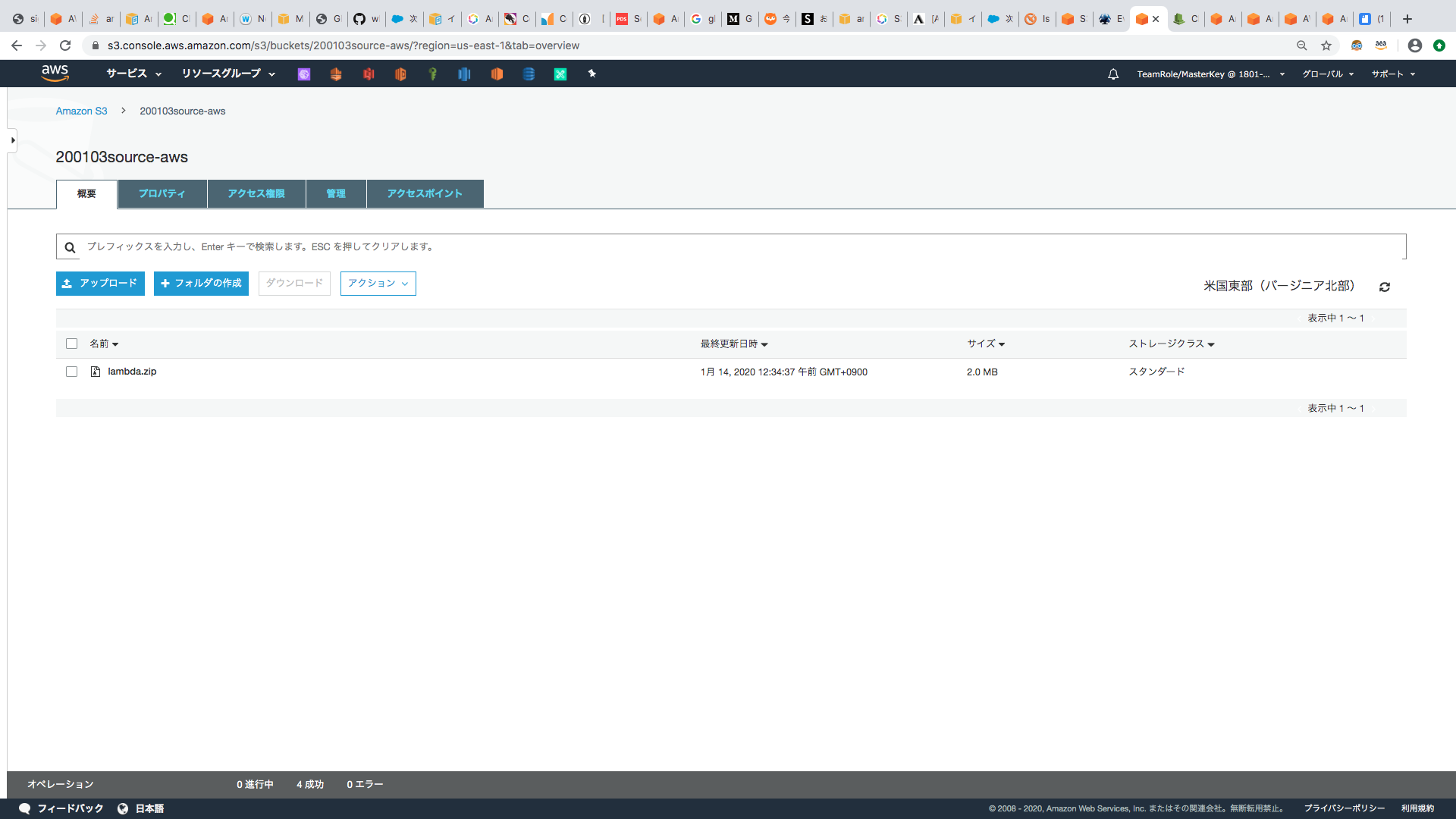
アップロード後、当該ファイルを選択し、オブジェクトURLのパスをコピーし、テキストファイルなどにペーストしてください。