自然言語処理を用いたPubMedのAbstractの抽出/構造化/可視化ハンズオン
本ハンズオンでは、下記のようなユースケースの想定して実施します。
課題
- PubMedでは定期的に論文がUploadされており、重要な情報源である。一方で、その情報量は多く、Abstractを中心に各研究者が読み込み自分の興味があるトピックが含まれるかを探しているため、工数が大きい。また、逆に工数が多いことから本来重要な論文の確認を漏らしてしまう可能性もある。
実現すること
- PubMed APIを利用し、Abstractを中心にクローリングを行う。Abstractは構造化された文章ではないため、医療用語も理解できるAIサービス 「Amazon Comperened Medical」を利用し文章を自動でタグ付けし「AWS Glue」でデータカタログ化を実施。カタログ化されたデータに対して「Amazon Athena」と「Amazon QuickSight」を使ってBI/可視化をおこなう。
実現しないこと/対象外
最終的に可視化した結果が、研究等の業務に使えるか?についてはハンズオンの対象外です
- 対象外
- PubMedにより取得したデータの内容自体についての洞察
- 対象
- 本ハンズオンではクラウドのサービスを利用することによってご自身の業務が、
- 「どのように」
- 「すぐに」
- 「簡単に」
- 「安く」
- 本ハンズオンではクラウドのサービスを利用することによってご自身の業務が、
構築できるか? を体感いただくことが目的となってます。
アーキテクチャー
- 下図のサーバーレスアーキテクチャにて作成していきます。
- サーバーレスアーキテクチャとは、サーバーをご自身で管理するのではなく、運用上の多くの責任を AWS にシフトさせることができるため、俊敏性とイノベーションを強化できます。サーバーレスのおかげで、アプリケーションとサービスを構築、実行する際に、サーバーに関して悩むことはなくなります。サーバーまたはクラスターのプロビジョニング、パッチ適用、オペレーティングシステムのメンテナンス、キャパシティーのプロビジョニングといったインフラストラクチャ管理のタスクが不要になります。
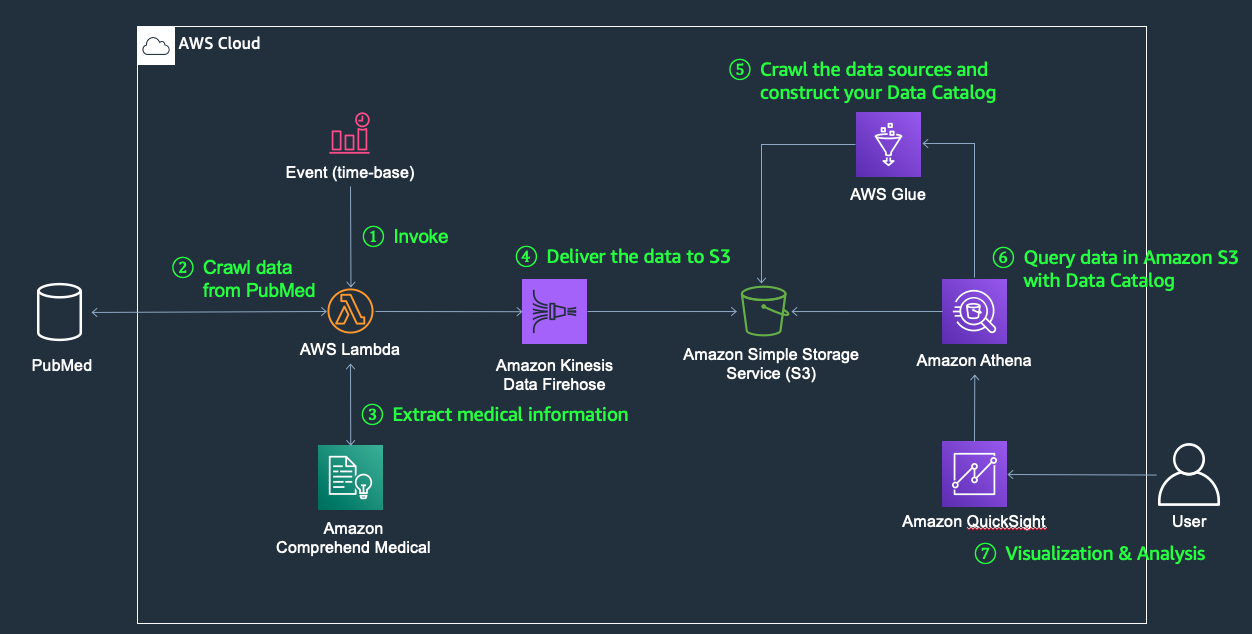
本ハンズオン内のワークフロー詳細
- Amazon EventBridge (スケジュール実行) AWS Lambda を実行
- Amazon Comprehend Medical で キーワード抽出・カテゴリを分類
- 結果をAmazon S3へ格納
- AWS Glue を利用してデータ構造を解析し、データカタログとして保存
- BIツール(Amazon QuickSight)で分析・可視化
それでは早速、始めてみましょう!
画面右中央の矢印をクリックして進めてください。