AWS ParallelCluster の起動と確認
ParallelCluster の起動
- Cloud9 のターミナルにコマンドを入力していきます。
- 以下のコマンドで ParallelCluster を作成・起動します。 (ここでは例として
pcluster01の名前でクラスタを構成しています) - 正常に ParallelCluster の構成が完了すると、下記のような
CREATE_COMPLETEのメッセージとマスターノードのアドレス情報などが出力されます。
完了まで約 10 分程度かかります。
pcluster create pcluster01- 出力例
Beginning cluster creation for cluster: pcluster01
Creating stack named: parallelcluster-pcluster01
Status: parallelcluster-mycluster - CREATE_COMPLETE
ClusterUser: centos
MasterPrivateIP: 10.0.0.132以下のようなメッセージが出た場合は、別の Private Subnet を作成し、config ファイルに指定する必要があります。手順がわからない場合は、ハンズオンオーガナイザーにご確認ください。 Your requested instance type (c5.xlarge) is not supported in your requested Availability Zone (us-east-1e). Please retry your request by not specifying an Availability Zone or choosing us-east-1a, us-east-1b, us-east-1c, us-east-1d, us-east-1f.
ParallelCluster の状態確認
pcluster では以下のようなコマンドを使用し、実行中のクラスタの状態を確認する事が可能です。
- クラスタ一覧
pcluster list- クラスタ情報確認
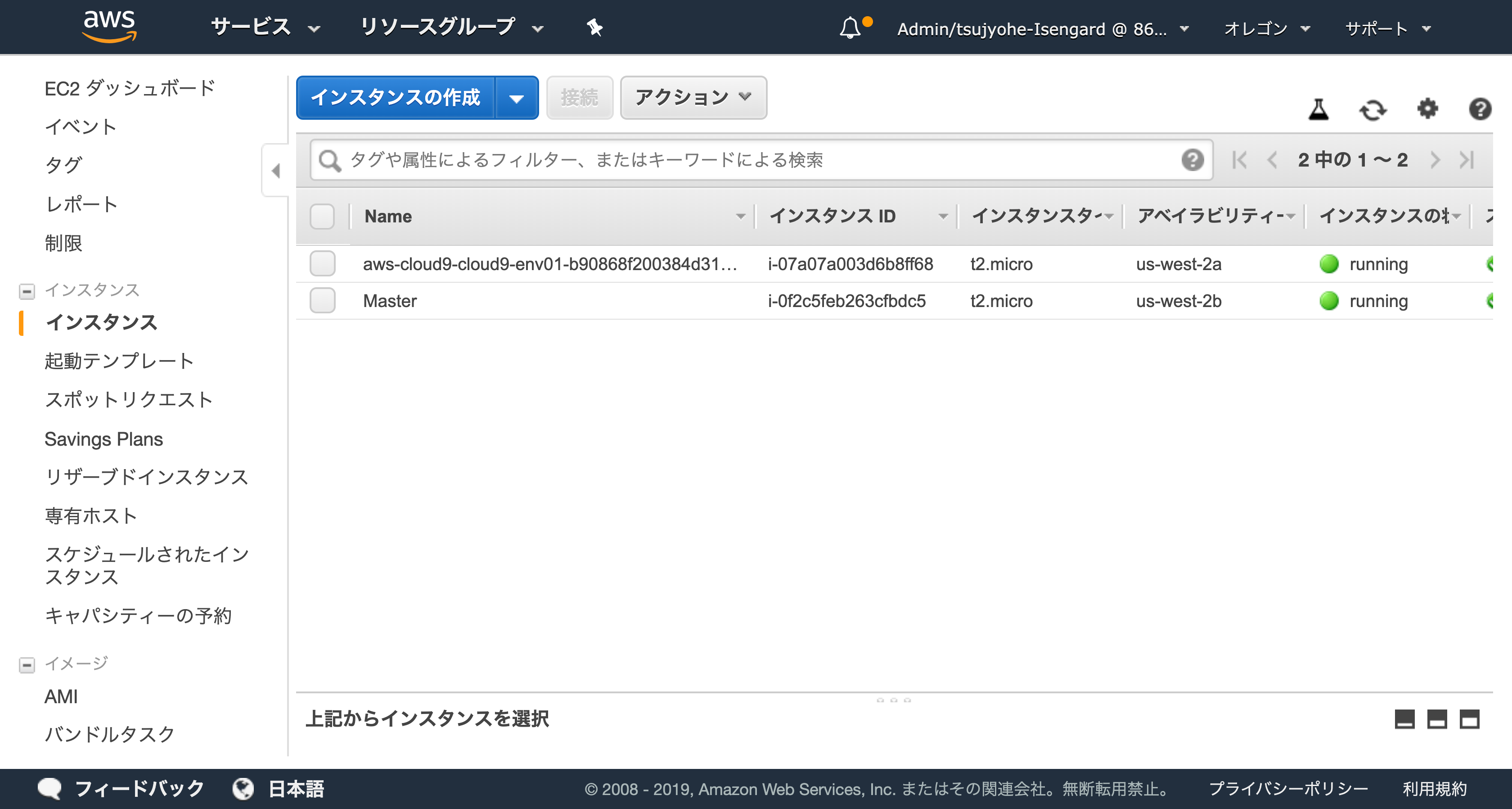
pcluster status pcluster01マネジメントコンソールから EC2 インスタンスのページにいき、立ち上がっているインスタンスを確認します。
- 他に何も起動していなければ Cloud9 用インスタンスと、ParallelCluster の Master server の 2 つのインスタンスが立ち上がっています。
ParallelCluster へのログイン
- 次のコマンドで ParallelCluster のヘッドノードにログインします。
~/environment/guest01-key.pemは先程 Cloud9 にアップロードした秘密鍵です。別の名前を使用している場合は置き換えてください。- SSH では、鍵ファイルの権限チェックがあるため、事前に
chmodコマンドで権限を600(Owner のみ読み書き可能)に変更しています。
chmod 600 ~/environment/guest01-key.pem
pcluster ssh pcluster01 -i ~/environment/guest01-key.pem- クラスタへの初回アクセス時には、ホスト確認メッセージが表示されるため、
yesと入力してください。
The authenticity of host '3.84.225.142 (3.84.225.142)' can't be established.
ECDSA key fingerprint is SHA256:pSnDp+HY3hH9ulqlWWx5G+H559s/fAmnSPWwI+zlcGA.
ECDSA key fingerprint is MD5:d8:2c:cf:91:9d:90:86:1f:5e:ee:32:05:7d:91:f3:1f.
Are you sure you want to continue connecting (yes/no)? yesParallelCluster の動作確認
SGE 編または、Slurm 編のいずれかを、ハンズオンオーナーの指示に従って実施してください。
- Master server にログインして動作確認を行います。
- 以下のコマンドは Master server 上で実行します。
スケジューラの確認
sinfo コマンド (Slurm) / qhostコマンド (SGE) により、起動中の Compute node の一覧を取得できます。
テスト用ジョブスクリプトの作成
以下のコマンドを実行して、sleepしてホスト名と日時を表示するだけの簡単なジョブファイル(job1.sh)を作成します。
ファイルが作成されていることを確認します。
cat job1.shジョブ投入
ジョブを投入するには、sbatch コマンド (Slurm) / qsub コマンド (SGE) を使用します。
ジョブ確認
squeue コマンド (Slurm) / qstat コマンド (SGE) により、ジョブキュー状態を表示します。
ジョブ実行が完了すると、squeue / qstat コマンドの出力からジョブの表示が無くなります。
Compute ノードが無い状態では、ジョブ投入後 ComputeFleet の起動に時間を要するため、ジョブが完了するまでに数分の時間を要します。
(時折り squeue / qstat コマンドを実行して状態の変化を確認してみましょう)
ジョブ実行結果
ジョブの実行結果を確認します。