性能結果サマリ
本章では、Keras Resnet-50 事前学習モデルを用いてCPU、Inferentia推論チップ(Neuronコア)、GPUそれぞれでの動作確認、性能測定を行いました。
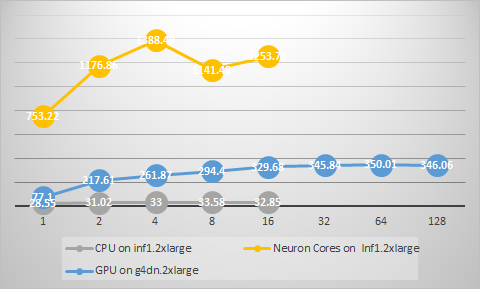
InferentiaとGPUは、ともにハードウェアによる推論処理のアクセラレータという点で推論性能の向上に寄与しますが、GPUがスループットを最大化するためにバッチ推論が必要となるのに対して、Inferentiaでは単一バッチにおいても高い性能を提供し、高いスループットと低いレイテンシの両立を実現しています。
Inferentia、GPUともにモデル自身の最適化を行うことにより、さらなる性能向上を図る余地がある点にご注意ください。 Inferentia上でのResnet50の更なる最適化についてはこちらをご参照ください。 NVIDIAでは学習済みモデルに追加の最適化を行うために、モデルコンパイラであるTensorRTを提供しています。
Amazon EC2 Inf1 インスタンスは、これまでクラウドで利用可能な最も低コストな推論インスタンスである Amazon EC2 G4 インスタンスよりも、最大 2.3倍 高いスループットと最大 70% 低い推論あたりのコストを実現します。