AWS Inferentia
機械学習 推論用プロセッサ AWS Inferentia は推論ワークロードを高性能かつ低消費電力で実行するために開発された、AWSによる独自設計の推論チップです。
1つの Inferentia チップは低電力で最大128 TOPS の性能を提供。1台のサーバーに最大16チップを搭載することで最大2,000 TOPS の性能を提供します。
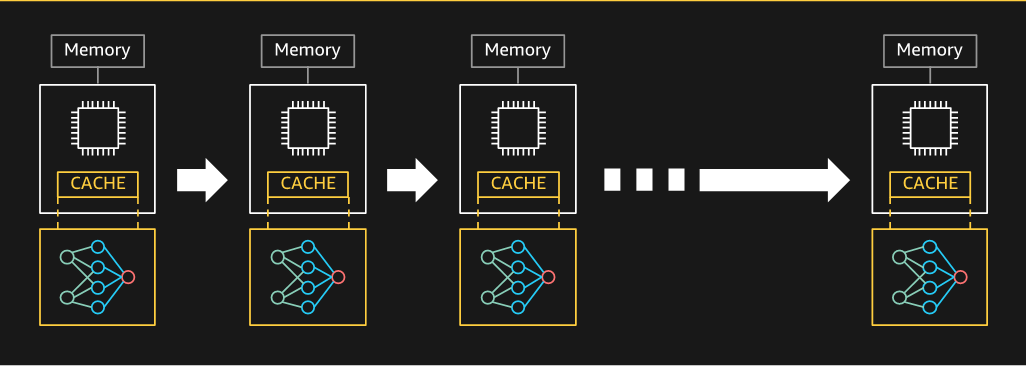
各 Inferentia チップは4つの Neuron コアと大規模オンチップメモリで構成されています。大規模なモデルがキャッシュ可能となることから Inferentia の プロセッシングコアである Neuron コアは、モデルへ高速にアクセスでき、推論レイテンシーの低下に大きく貢献します。
Inferentia は複数のデータ型(int8、FP16 および BFloat16)をサポートしています。FP32で構築された学習済みモデルは、BFloat16を使用して高速に実行可能です。
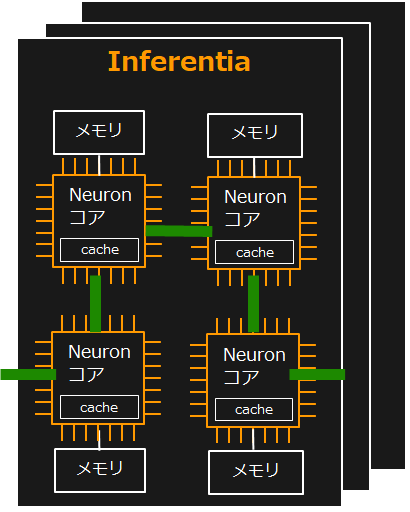
またInferentia チップは、高速相互接続テクノロジーを実装しているため、複数のチップを大きな仮想デバイスとして利用可能です。大規模モデルを複数のInferentiaチップ、Neuronコア間で分割することにより、最大64個のNeuronコアをパイプライン的に接続し、高スループット、低レイテンシを実現します。